1.House Of Einherjar
其实就是off by null+堆叠
隐式链表:通过pre_size找上一个堆块,通过size找下一个堆块
补充一写,还是有些不同
当释放堆块下一个块是top_chunk的时候,free会与相邻后向地址进行合并,并且放入top_chunk,在申请时,就会从前面那个堆块的地址中申请出来
两个相邻的堆块,前一个堆块是free状态,free后一个堆块,会和前一个堆块合并也就是unlink,如何找到前一个堆块,根据的是pre_size为的大小(其实就是两个堆块头部的偏移),还要绕过unlink,也就是前一个堆块的size位与后一个堆块的pre_size位相等
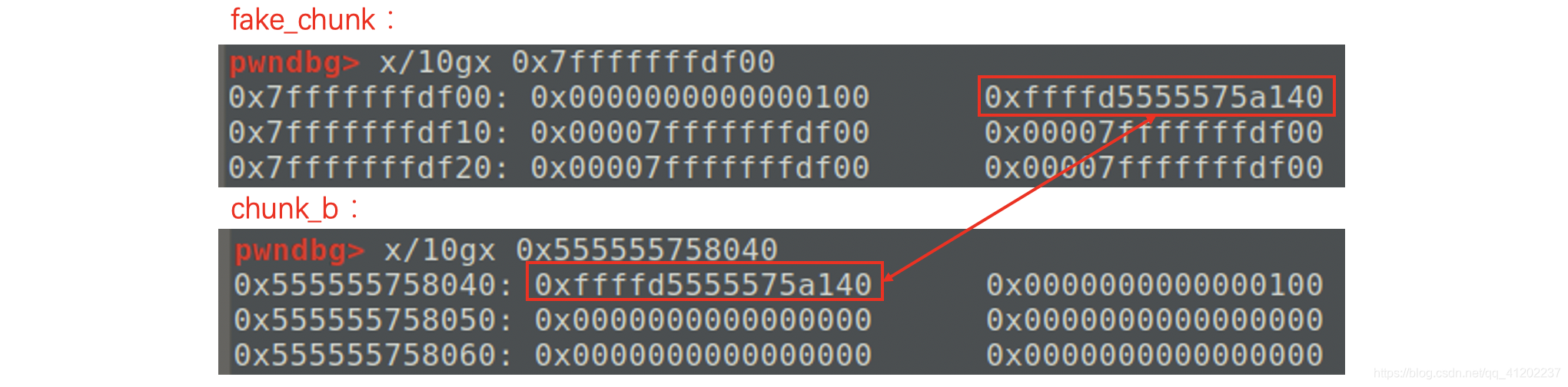
虽说是相邻的(并且已经被free的堆块必须在前面也就是低地址),但是加入伪造了一个堆块在栈上
fake_chunk的prev_size、size部分设置为0x100,fd、bk、fd_nextsize、bk_nextsize设置为fake_chunk自身地址,这样做是为了绕过free()函数后向合并时最后的unlink检查

我们可以将后一个堆块的pre_size位设为负数,就可以找到栈上的那个堆块
0x555555758049-0x7fffffffdf00=0xffffd5555575a140
例题:tinypad
当got表不可以打的时候,我们可以打free_hook,free_hook不可打,利用__environ,泄露栈地址打返回地址,返回地址不可打,我们可以打main函数的返回地址

将堆块伪造在0x602040

pre_size位设置的和将要被free的堆块大小相同,size位设为两个堆块的偏移
fd、bk、fd_nextsize、bk_nextsize设置为fake_chunk自身地址
将要被free的堆块在0x6030f0
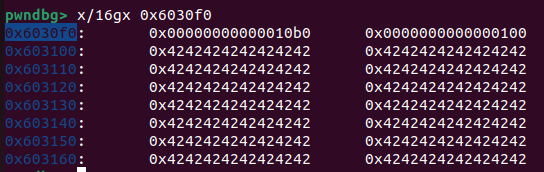
将pre_size设为两个堆块的偏移,将利用0ff by null 将 pre_inuse设置为0
然后free堆块,top_chunk的地址就编程伪造堆块的地址了(0x602040)
显示不是但是申请就是
存储堆块指针的数组在0x602140
我们从0x602040申请0xe0,在申请一个堆块数据段刚好申请在0x602140
req = 0x602140-0x602040 - 0x20(0x10)

然后在申请一个堆块,这个堆块的数据段,就刚好位于储存指针的数组的位置,然后就是更改指针,实现任意地址写了
然后就是如何泄露栈地址,与更改返回地址了

这样构造
将堆块1的指针改为__environ,然后打印堆块1就可以泄露栈地址
将堆块2的指针改为记录堆块1指针数组的地址,这样通过堆块2,更改堆块1的指针
通过将堆块1的指针改为返回地址的栈的值

然后更改堆块1的内容为ogg即可,这道题改的是main函数的返回地址,free_hook和返回地址都改不了,不知道为啥

1 | dd(0xe8, b"A"*0xe8) |
2.house of froce
控制top_chunk的地址
top_chunk的size位大小有显示,我们只能申请堆块在堆得内存区域,而申请不到在bss段上(bss段在堆得下方,所以永远申请不到),如果我们改变top_chunk的size位使他为-1(0xffffffffffffffff),我们就可以申请一个超级大的堆块,使他转一圈转到bss段上
在2.23和2.27的libc版本中,由于没有对top chunk的size合法性进行检查,因此如果我们能够通过堆溢出控制top chunk的size位为-1
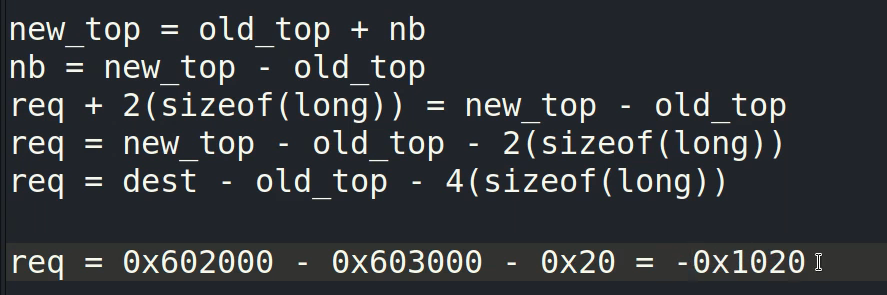
如何计算:
req = dest-old_top - 0x20(0x10)
dest就是我们将要写入的地址
1.如何修改top_chunk的size位
申请一个挨着top_chunk的堆块堆溢出就可以修改
2.需要泄露出top_chunk的地址,这道题直接打印出每个堆块的指针的地址,通过紧挨着top_chunk那个堆块就可以算出
3.这道题打malloc_hook,为什么没有用ogg
因为知道指针的地址,也就知道/bin/sh写入的地址,将malloc_hook改为system,申请堆块时候,写上/bin/sh的地址就可以(或者通过realloc调整栈帧)
例题:gyctf_2020_force
1 | libc_base = add(0x200000,b'aaaa')+0x200ff0 |
3.house of lore
主要就是围绕smallbin的
1.堆块如何进入smallbin,当unsortbin中有一个堆块,在申请一个堆块,大于unsortbin中的堆块,且unsortbin中的堆块不能合并,或者合并后也达不到大小,就会把unsortbin放入smallbin当中
2.如何伪造堆块到smallbin中
首先申请一个0x100的堆块
在栈上伪造两个堆块,伪造他们的fd与bk,就像下面的一样
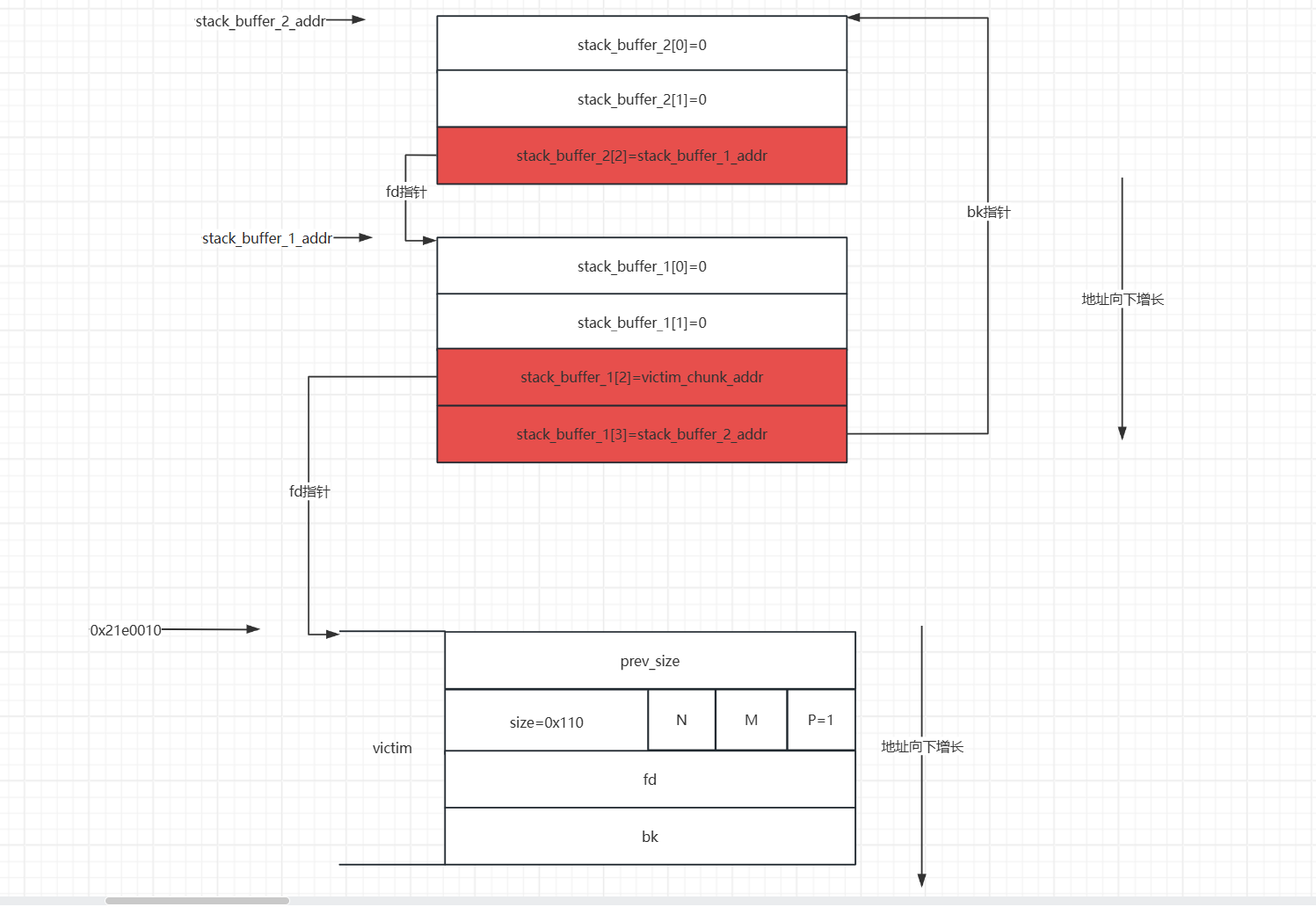
就像这样,然后将victim free掉(在这之前再申请一个堆块,防止与top chunk合并),他会进入unsortbin,然后,在申请一个大于他的堆块,他就会进入smallbin,然后再修改victim的bk指针,这时栈上的两个假的堆块就会进入smallbin中
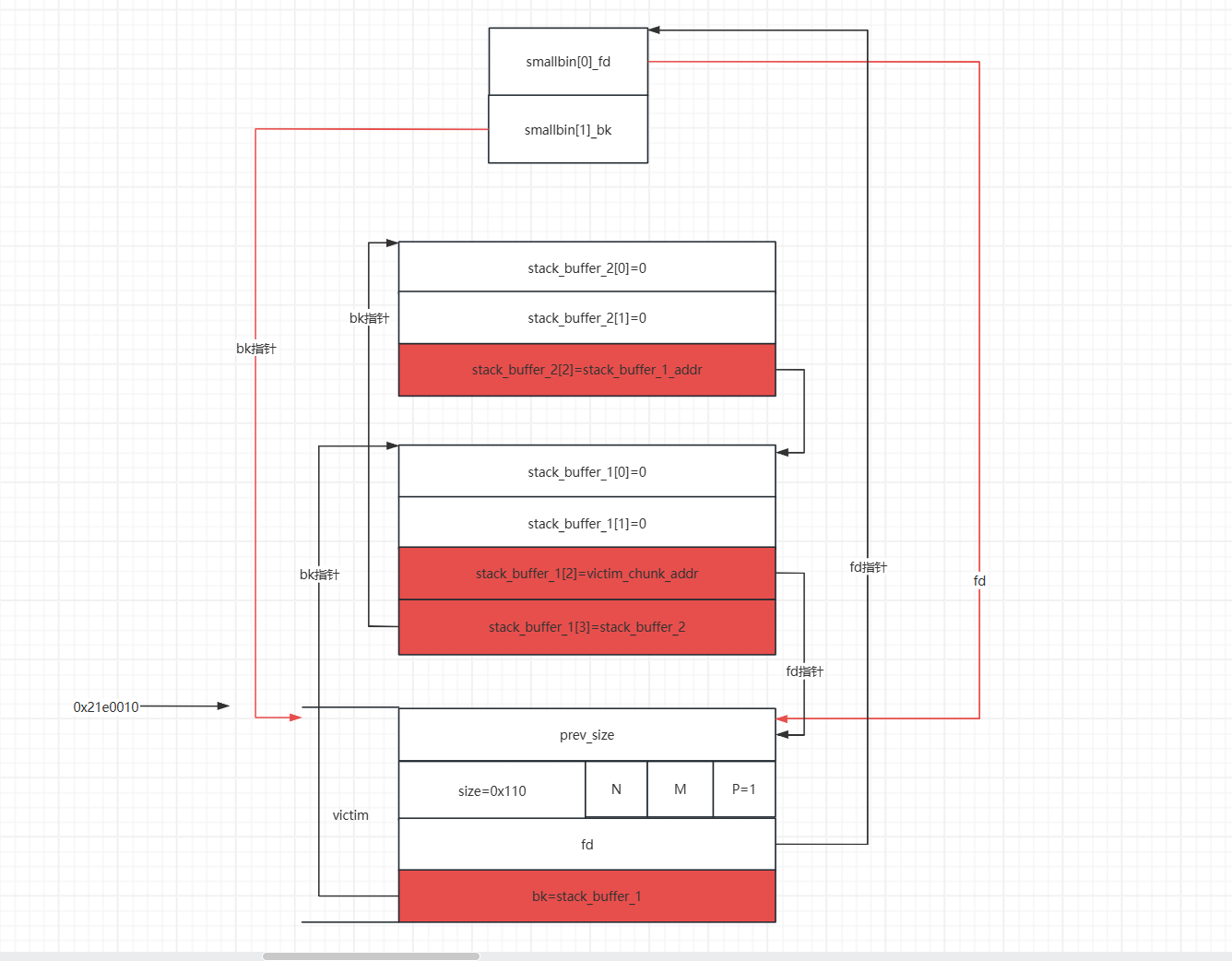
然后我们再申请一个,victim就会被申请出来,smallbin先进先出,再申请一个,栈地址上的堆块就可以申请出来,就可以写数据,覆盖返回地址
4.House of Orange
概述 ¶
House of Orange 的利用比较特殊,首先需要目标漏洞是堆上的漏洞但是特殊之处在于题目中不存在 free 函数或其他释放堆块的函数。我们知道一般想要利用堆漏洞,需要对堆块进行 malloc 和 free 操作,但是在 House of Orange 利用中无法使用 free 函数,因此 House of Orange 核心就是通过漏洞利用获得 free 的效果。
原理 ¶
如我们前面所述,House of Orange 的核心在于在没有 free 函数的情况下得到一个释放的堆块 (unsorted bin)。 这种操作的原理简单来说是当前堆的 top chunk 尺寸不足以满足申请分配的大小的时候,原来的 top chunk 会被释放并被置入 unsorted bin 中,通过这一点可以在没有 free 函数情况下获取到 unsorted bins。
我们总结一下伪造的 top chunk size 的要求
- 伪造的 size 必须要对齐到内存页(addr+size是0x1000(4kb)对齐的)
因此我们伪造的 fake_size 可以是 0x0fe1、0x1fe1、0x2fe1、0x3fe1 等对 4kb 对齐的 size
- size 要大于 MINSIZE(0x10)
- size 要小于之后申请的 chunk size + MINSIZE(0x10)
- size 的 prev inuse 位必须为 1
之后原有的 top chunk 就会执行_int_free从而顺利进入 unsorted bin 中。
5.house of rabbit
利用触发 malloc consolidate,将fastbin的堆块放入unsortbin时候不会对size位进行检查,来实现堆叠
触发malloc consolidate条件
1.fastbin当中没有合适大小的堆块,先合并,合并不够就会被放入unsortbin(smallbin)这时不会对size位进行检查就触发堆叠了
2.top chunk不够了
6.house of botcake
glibc2.29~glibc2.31,tcache加入了 key 值来进行 double free 检测,以至于在旧版本时的直接进行 double free 变的无效,所以自然就有了绕过方法,绕过方法其中比较典型的就是 house of botcake,他的本质也是通过 UAF 来达到绕过的目的
当 free 掉一个堆块进入 tcache 时,假如堆块的 bk 位存放的 key == tcache_key , 就会遍历这个大小的 Tcache ,假如发现同地址的堆块,则触发 Double Free 报错。
从攻击者的角度来说,我们如果想继续利用 Tcache Double Free 的话,一般可以采取以下的方法:
之前只是检查链表的上一个,这次是检查全部的链表
从攻击者的角度来说,我们如果想继续利用 Tcache Double Free 的话,一般可以采取以下的方法:
- 破坏掉被 free 的堆块中的 key,绕过检查(常用)
- 改变被 free 的堆块的大小,遍历时进入另一 idx 的 entries
- House of botcake(常用没有edit)
1.free后用uaf改bk,然后就可以再次free
2没学
3.House of botcacke 合理利用了 Tcache 和 Unsortedbin 的机制,同一堆块第一次 Free 进 Unsortedbin 避免了 key 的产生,第二次 Free 进入 Tcache,让高版本的 Tcache Double Free 再次成为可能。
1 | for i in range(7): |
堆块8进入unsortbin
1 | free(7) |
堆块8与堆块7合并
1 | malloc(0x100) |
tcachebin中就空出来一个
然后再次
1 | free(8) |
这时8被free两次,一次在unsortbin中,另一次在tcachebin中,而且形成堆叠,8在7这个合并的大堆块中
1 | add(11,0x150,payload) |
申请一个大堆块,改堆块8的fd
tcachebin attack
提问:为什么不能先free(7)后free(8)
因为后面double free free(7),unsortbin链表就被破坏了

更高版本没有edit tcachebin attack
1 | for i in range(7): |
7,8堆块合并进入unsortbin
1 | add(10,0x210,b'\x10') |
将他两个申请出来,但是有uaf,所以7堆块和10堆块的指针指向同一块地址
1 | add(11,0x100,b'/bin/sh\x00') |
将tachebin空出来一个
1 | free(8) |
进入tachebin
1 | free(10) |
free10,又将10申请出来,12就可以覆盖到8
7.House-of-Corrosion
通过改bins的大小限制,使他可以存无限大的堆块的指针(就是往后面存),从而实现往任意地址写一个堆指针
但是只能在管理堆bins的后面
首先我们要修改bins的大小(任意地址写,unsortbinattack等)
例子1:fastbin
fastbinY[0]=0x7ffff07dcfc50
_IO_list_all=0x7ffff07dd06c0
chunk size = (delta * 2) + 0x20 ,delta为目标地址与fastbinY的offset
在这个例子中,chunk大小应该是(0x7ffff7dd06c0-0x7ffff7dcfc50)*2+0x20=0x1500字节
例子2:tcachebin
改mp_.tcache_bins = obstack_exit_failure-0x20
mp_.tcache_bins = libc.sym[‘obstack_exit_failure’]+libc_base
https://xz.aliyun.com/news/15532
entries[0] = 0x555555605090
因为他这个是在堆上,所以我们可以直接让他在第一个堆块里面,然后改他为free_hook,然后再申请出来就可以了
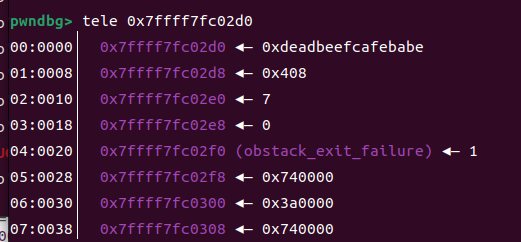
我们将这个本来是0x40改成一个大的值之后当申请大的堆块他也会进入tcachebin,然后他的指针就会被存起来,在这个初始化堆块,0x5090就是存大小为0x20链表头的堆块指针,依次往后所以我们申请一个大堆块,他的指针就会往后面写,写道我们申请的第一个堆块我们就可以利用第一个堆块修改它

free大堆块之后
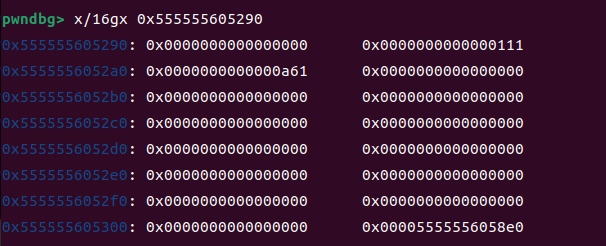
但是bins里面不会有,但是它实际上是有的
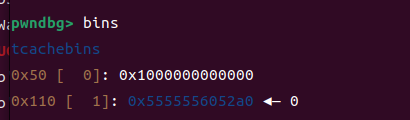
所以我们改成free_hook之后,直接申请就可以申请出来
1 | add(0x100,b'a') #0 |