原理:
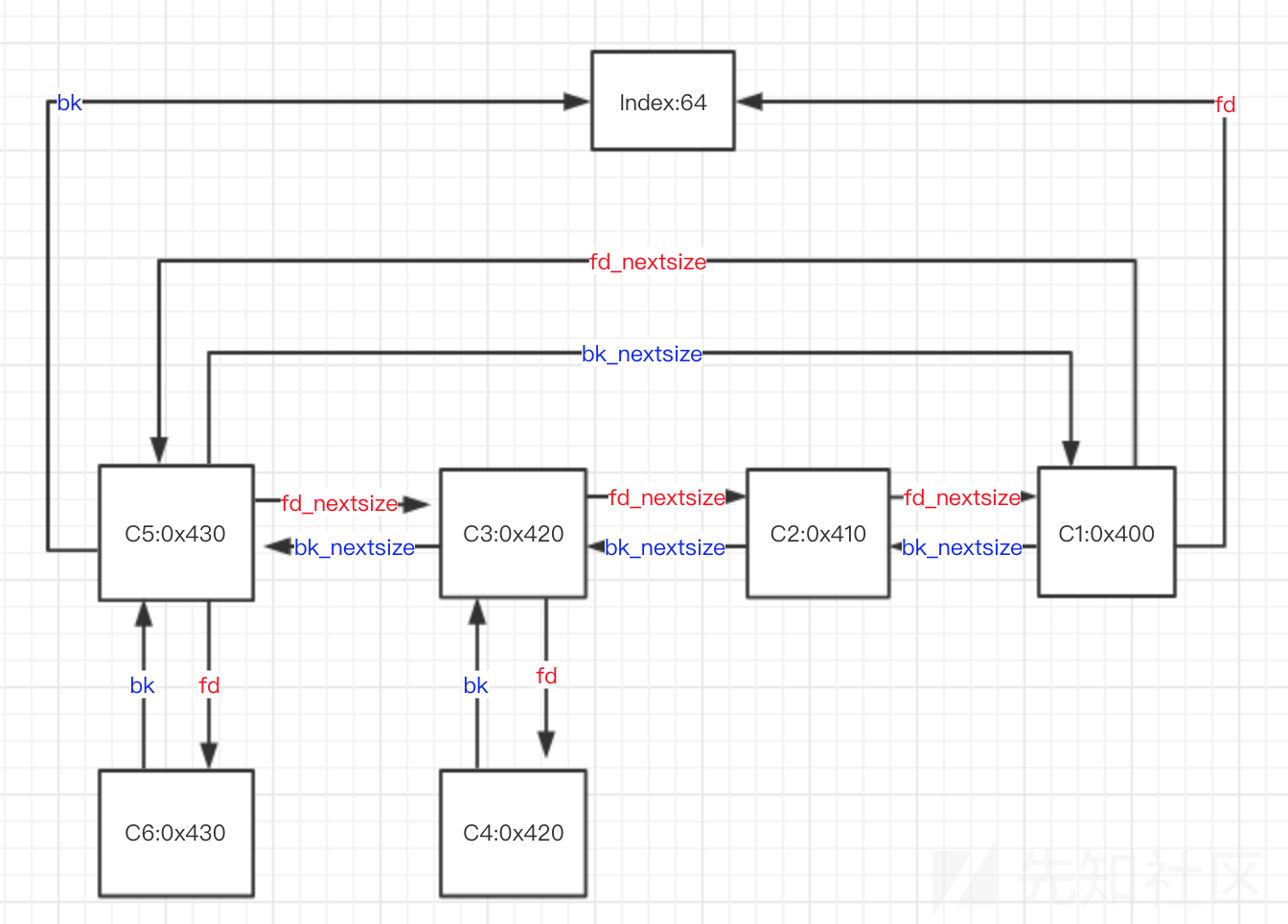
Large Bin结构
large bin中一共包括63个bin,每个bin中的chunk大小不一致,而是出于一定区间范围内。此外这63个bin被分成了6组,每组bin中的chunk之间的公差一致
按范围递增(范围随 index 扩大):- index 0~3:0x400~0x800 字节- index 4~59:0x800~ 几 KB- index 60~62:几 MB 至更大
大于512(1024)字节的chunk称之为large chunk,large bin就是用于管理这些large chunk的
被释放进Large Bin中的chunk,除了以前经常见到的prev_size、size、fd、bk之外,还具有fd_nextsize和bk_nextsize:
fd_nextsize,bk_nextsize:只有chunk可先的时候才使用,不过用于较大的chunk(large chunk)
fd_nextsize指向下一个与当前chunk大小不同的(小的)第一个空闲块,不包含bin的头指针
bk_nextsize指向上一个与当前chunk大小不同的(大的)第一个空闲块,不包含bin的头指针
这里下一个上一个相较于链表头部,链表头部往下堆块的地址变小
fd_nextsize方向 → size 递减bk_nextsize方向 → size 递增
一般空闲的large chunk在fd的遍历顺序中,按照由大到小的顺序排列。这样可以避免在寻找合适chunk时挨个遍历
Large Bin的插入顺序
在index相同的情况下:
1、按照大小,从大到小排序(小的链接large bin块)
2、如果大小相同,按照free的时间排序
3、多个大小相同的堆块,只有首堆块的fd_nextsize和bk_nextsize会指向其他堆块,后面的堆块的fd_nextsize和bk_nextsize均为0
4、size最大的chunk的bk_nextsize指向最小的chunk,size最小的chunk的fd_nextsize指向最大的chunk
我们从链表头部开始遍历,直到找到第一个 size 大于等于待插入 chunk 的链表,找到后判断链表的 size 是否等于待插入chunk的size,如果相等,直接将这个 chunk 插入到当前链表的第二个位置,如果不相等,说明待插入的chunk比当前链表头结点的 size 大,那么我们将待插入的chunk作为当前链表的头结点,插入到符合size的bin index后
例:how2heap
1 | 1 // gcc -g -no-pie hollk.c -o hollk |
free(p1)
free(p2)

malloc(0x90)
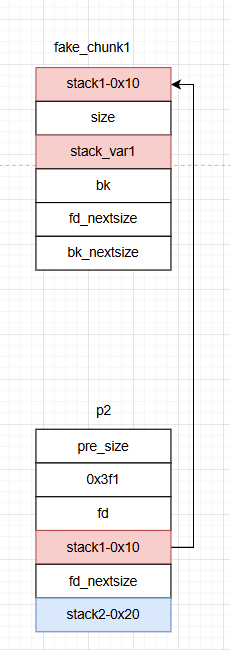
从堆块1中切割,遍历时将堆块1放入smalbin,堆块2largebin,切割堆块1,堆块1,进入unsortbin
free(3)

然后修改p2,size位改为0x3f1,bk_nextsize = stack2-0x20 ,bk = stack1-0x10
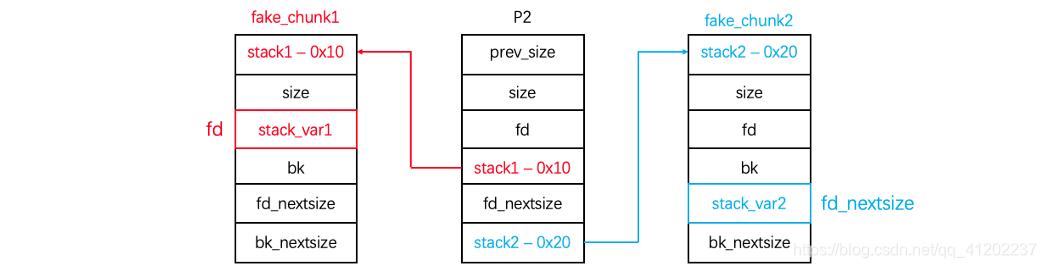
malloc(0x90)
还是从堆块1中切割,堆块1进入smallbin,堆块3进入largebin,切割堆块1,堆块1,进入unsortbin
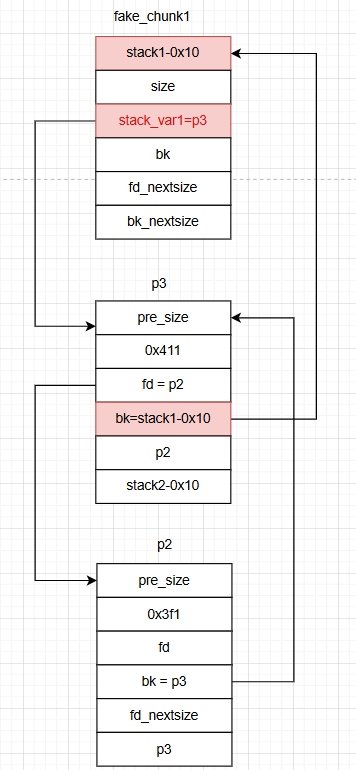
在堆块3挂入largebin的时候P3_size > P2_size 就会执行

1 | else |
执行之前: 执行之后:
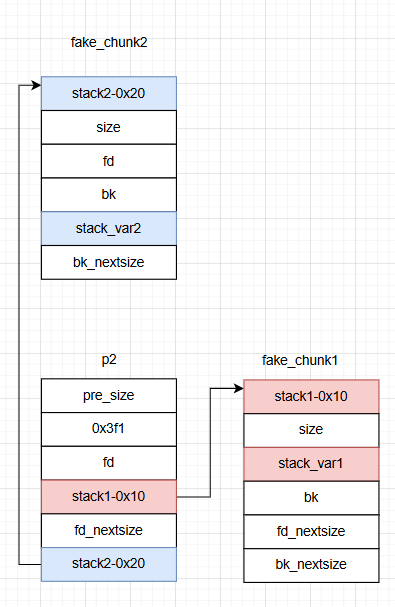
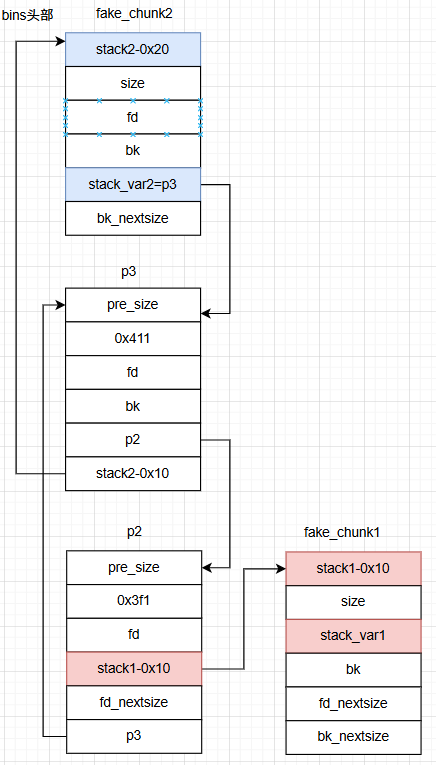 这个过程其实就是让p3加在fake_chunk2 与p2之间使得fake_chun2的fd_nextsize=p2
这个过程其实就是让p3加在fake_chunk2 与p2之间使得fake_chun2的fd_nextsize=p2
P2->bk_nextsize->fd_nextsize = stack_var2_addrP3->bk_nextsize = P2->bk_nextsizeP3->bk_nextsize->fd_nextsize = P3
那么就可以导出结论:stack_var2的值 = P3头指针,所以stack_var2变量中的内容就被修改成了P3的头指针
看图片中红色的字
还有fd与bk
bck = P2->bk; //bck等于P2的bk
值得注意的是bck是p2的bk指针也就是fake_chunk的头部,后面p2的bk指针变了,但是bck没变还是fake_chunk的头部

1 | mark_bin(av, victim_index); |
执行之前: 执行之后:
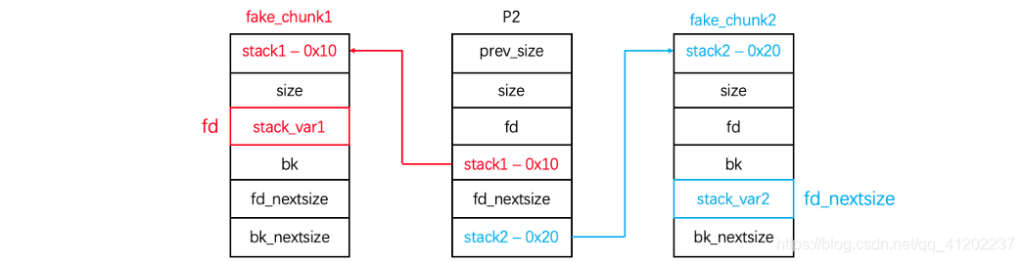
这个过程其实就是让p3加在fake_chunk2与p2之间使得fake_chun1的fd=p3
总结:
2.30版本及之前
在2.30以前,缺少对largebin attack的检查,所以我们可以大胆的进行伪造,在插入一块新的largebin时,会将当前堆块的bk->fd和bk_nextsize->fd_nextsize写成当前堆块的地址,如下图,所以如果根据下图把bk构造成targetaddr1-0x10,bk_nextsize构造成targetaddr1-0x20,即可在插入largebin时(插入的要大于P2)触发unlink进行同时改写两处地址为heapaddr(插入堆块的头部)
2.30之后
2.30之后会进行如下两个检查
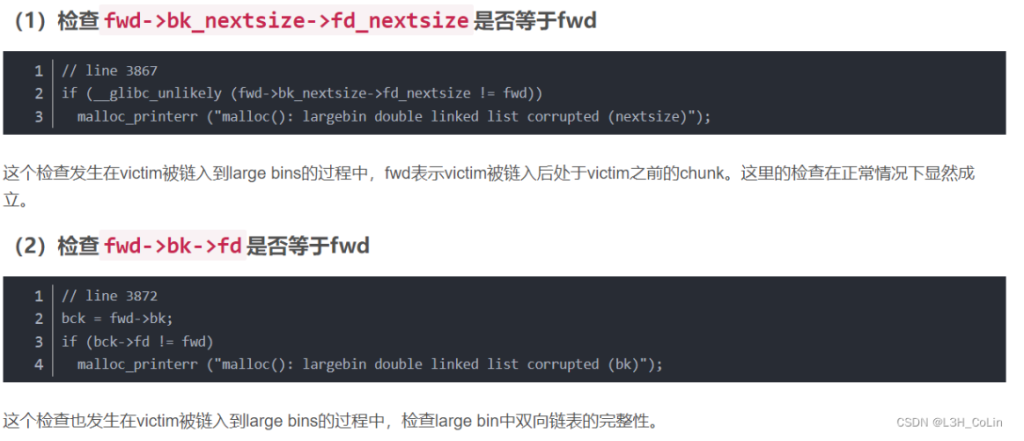
这就导致在申请的堆块大于最小chunk时我们不能随意地修改bk和bk_nextsize了,为了绕过这个检查,我们要使得当前申请的堆块小于目前的最小chunk(即它是新的最小),还记得为什么吗?上文中红色的部分,因为如果它是最小它会直接被链入,没有这些乱七八糟的检查,但这也导致他只能任意写bk_nextsize指向的位置,所以在这种情况下,可以将bk_nextsize赋成targetaddr-0x20
1 | assert (chunk_main_arena (bck->bk));//断言bck->bk属于main_arena |
这段代码与unsorted_bins、large_bins有关,这是从unsorted_bins里提取出来的堆块((unsigned long) (size))与large_bins里的最小堆块((unsigned long) chunksize_nomask (bck->bk))进行比较,如果unsorted出来的堆块更小,就执行如上操作。
所以我们先往largebin里面放一个堆块,然后unsortbin里面有个比largebin已有的小的堆块,然后申请一个比已有unsortbin打的堆块,unsortbin中的堆块就会进入largebin,完成往任意地址写堆块地址
模板:
1 | add(0,0x450) |
例:how2heap
1 | #include<stdio.h> |