tcache介绍
- 1.每个线程默认使用64个单链表结构的bins,每个bins最多存放7个chunk,64位机器16字节递增,从0x20到0x410,也就是说位于以上大小的chunk释放后都会先行存入到tcache bin中,当申请大于7个就会放入fastbins,但是tcache优先级高于fastbins,tcache先被申请出来
- 2.对于每个tcache bin单链表,它和fast bin一样都是先进后出,而且prev_inuse标记位都不会被清除,所以tcache bin中的chunk不会被合并,即使和Top chunk相邻。
- tcache机制出现后,每次产生堆都会先产生一个0x250大小的堆块,该堆块位于堆的开头,用于记录64个bins的地址(这些地址指向用户数据部分)以及每个bins中chunk数量。在这个0x250大小的堆块中,前0x40个字节用于记录每个bins中chunk数量,每个字节对应一条tcache bin链的数量,从0x20开始到0x410结束,刚好64条链,然后剩下的每8字节记录一条tcache bin链的开头地址,也是从0x20开始到0x410结束。还有一点值得注意的是,tcache bin中的fd指针是指向malloc返回的地址,也就是用户数据部分,而不是像fast bin单链表那样fd指针指向chunk头。
tcache绕过
1.绕过tcache进行fastbin attack申请大小相同的七个堆块,然后在申请一个,free7个,free最后申请的那个就会进入fastbin
2.绕过tcache bin ,利用unsorted bin,申请大于0x400的堆块,要防止堆块和top chunk合并
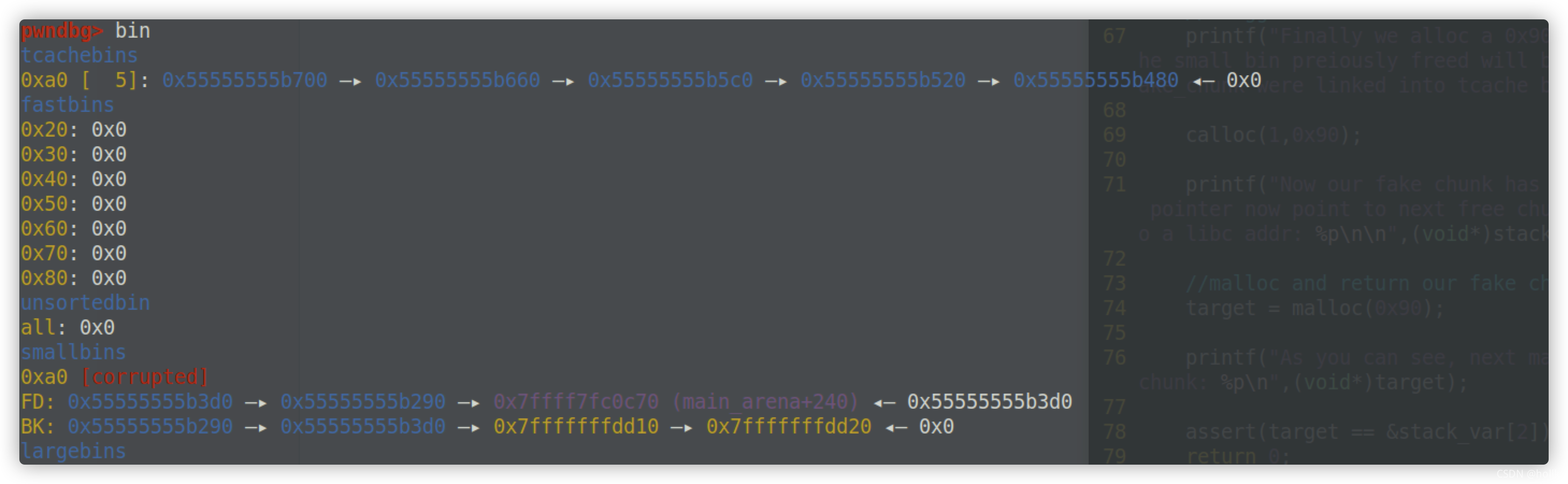
3.使用calloc
calloc函数不会分配tcache bin中的堆块,因此如果题目中出现了calloc函数,我们可以想到利用该函数直接绕过tcache,从而获得其它bin上的chunk。
申请8个free8个使用calloc申请就会直接获取ast bin上的chunk块(正常是先会申请tcache上的)
tcache extend
1.tcache机制情况下的chunk extend,相比较于fastbin,tcache机制的加入使得漏洞利用更简单,因此实现chunk extend也更轻松,不用正确标记next chunk的size,只需要修改当前chunk的size。我们free再malloc后就可以获得对应大小的chunk
2.glibc-2.27版本引入了tcache,但此时还没引入tcache的检测,所以基本就是想怎么申请都行,直接利用use aftr free,修改fd为__malloc/free_hook
3.glibc-2.31版本引入了tcache长度保护,会检测bins上的个数是否和申请的匹配,不匹配的话没法申请出来。比如说tcache_bins上0x90的chunk个数为0,但是我们gdb里显示我们劫持的地址还没申请出来,这个时候如果malloc的话是无效的,没法申请出来。所以要是想劫持hook地址,我们就需要至少两个堆块被free进了tcache_bins里,修改头指针fd为hook即可
1.tcachebin uaf
1.glibc-2.27的tcachebin改fd指针申请堆块不会检查,所以可以随便改(也就是打malloc/free不用找size位为0x7f的了),这使得打free_hook,更简单
2..glibc-2.31版本引入了tcache长度保护,会检测bins上的个数是否和申请的匹配,比如说tcache_bins上0x90的chunk个数为0,但是我们gdb里显示我们劫持的地址还没申请出来,这个时候如果malloc的话是无效的,没法申请出来。所以要是想劫持hook地址,我们就需要至少两个堆块被free进了tcache_bins里,修改最后被free的那个堆块的fd指针
1 | for i in range(8): |
先申请7个,在申请一个就会在unsortbin,利用这个泄露libc,修改最后一个tcachebin的fd,申请两次就把free_hook申请出来了
2.tcachebin off by null
1 | for i in range (7): |
具体就是绕过tcachebin,将堆块申请在unsortbin就行具体就不解释了,和正常的off by null一样
3.tcachebin off by one
让合并后的堆块大于0x400,进入unsortbin就可以
1 | d(0x18, 'aaaa') #0 |
4.tcache stashing unlink attack
知识点:
1.当系统需要分配内存,且 tcache bin 和 fastbin 中都找不到合适的堆块时,就会到 unsorted bin 上寻找。如果申请的内存堆块小于 unsorted bin 中某个堆块的大小,那么会将该内存块切割后返回给用户,剩下的部分仍然保存在 unsorted bin 上;如果申请的内存堆块大于 unsorted bin 上存放的堆块大小,那么会从 Top chunk 上重新分割,此时就会把 unsorted bin 上的堆块按照大小放回 small bin 和 large bin 中。
2.当从smallbin中申请出来一个堆块,smallbin剩余的堆块就会被挂进tcachebin,并且只会检查第一个被挂进tcachebin的堆块
利用前提:有calloc
首先申请9个堆块,先释放3-8,再将堆块1,释放,最后释放0,2
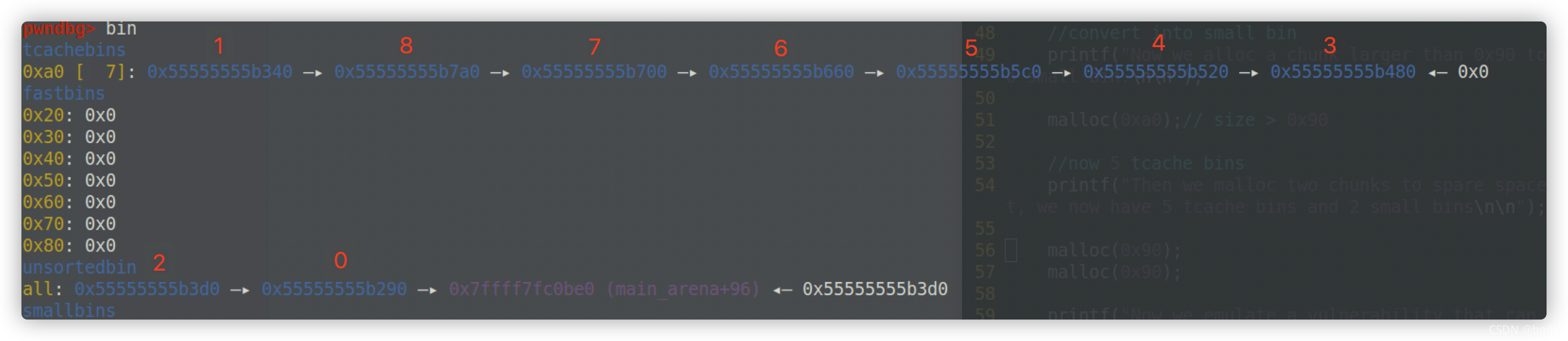
解释:这样目的是为了后面申请0xb0的堆块,tcache bin 和 fastbin 中都找不到合适的堆块,且unsortbins也不能合并(因为不相邻),这样最后会从top_chunk中新申请一个0xb0(data部分为0xa0)大小的堆块,并且将unsorted bin中的两个堆块,按照大小排列在small bin中:
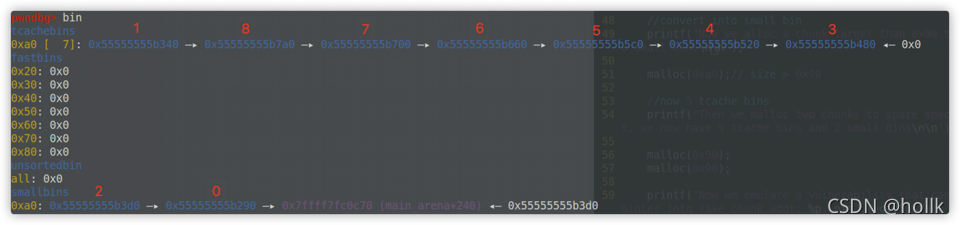
然后在申请两个0xa0的堆块,将tcache bin空出来
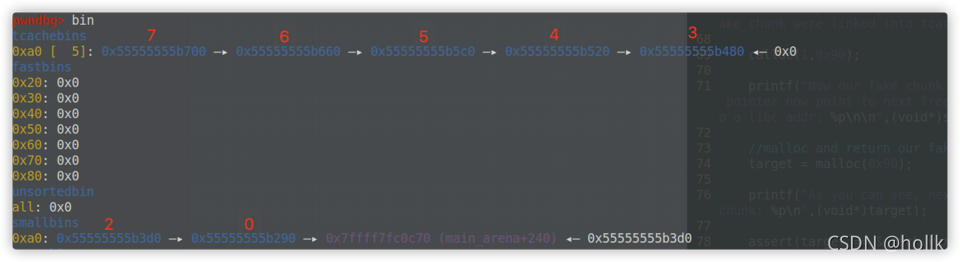
将2的bk改为任意地址,然后用calloc申请堆块,堆块0就会被申请出来,堆块2,与伪造堆块2后面的堆块就会被放入tcache bin

5.高版本没有edit tcachebin attack
glibc2.29~glibc2.39,tcache加入了 key 值来进行 double free 检测,以至于在旧版本时的直接进行 double free 变的无效,所以自然就有了绕过方法,绕过方法其中比较典型的就是 house of botcake,他的本质也是通过 UAF 来达到绕过的目的
当 free 掉一个堆块进入 tcache 时,假如堆块的 bk 位存放的 key == tcache_key , 就会遍历这个大小的 Tcache ,假如发现同地址的堆块,则触发 Double Free 报错。
从攻击者的角度来说,我们如果想继续利用 Tcache Double Free 的话,一般可以采取以下的方法:
之前只是检查链表的上一个,这次是检查全部的链表
从攻击者的角度来说,我们如果想继续利用 Tcache Double Free 的话,一般可以采取以下的方法:
- 破坏掉被 free 的堆块中的 key,绕过检查(常用)
- 改变被 free 的堆块的大小,遍历时进入另一 idx 的 entries
- House of botcake(常用没有edit)
1.free后用uaf改bk,然后就可以再次free
2没学
3.House of botcacke 合理利用了 Tcache 和 Unsortedbin 的机制,同一堆块第一次 Free 进 Unsortedbin 避免了 key 的产生,第二次 Free 进入 Tcache,让高版本的 Tcache Double Free 再次成为可能。
1 | for i in range(7): |
堆块8进入unsortbin
1 | free(7) |
堆块8与堆块7合并
1 | malloc(0x100) |
tcachebin中就空出来一个
然后再次
1 | free(8) |
这时8被free两次,一次在unsortbin中,另一次在tcachebin中,而且形成堆叠,8在7这个合并的大堆块中
1 | add(11,0x150,payload) |
申请一个大堆块,改堆块8的fd
tcachebin attack
提问:为什么不能先free(7)后free(8)
因为后面double free free(7),unsortbin链表就被破坏了

1 | for i in range(7): |
7,8堆块合并进入unsortbin
1 | add(10,0x210,b'\x10') |
将他两个申请出来,但是有uaf,所以7堆块和10堆块的指针指向同一块地址
1 | add(11,0x100,b'/bin/sh\x00') |
将tachebin空出来一个
1 | free(8) |
进入tachebin
1 | free(10) |
free10,又将10申请出来,12就可以覆盖到8
5.高版本glibc的tcache和fastbin指针加密机制
高版本tcachebin有加密机制,当free后堆块地址会加密,我们改fd指针,他会解密,然后就错了,所以我们先按照他的方法加密,写进去他解密就是对的
加密:原来指针^加密指针>>12
heap = u64(p.recv(5).ljust(8, b’\x00’))<<12
fd=(fd)^(heap)>>12